
Using computer vision to detect and classify corrosion
Corrosion is a serious safety concern. Severe corrosion can cause hazardous leaks or destabilize large structures. In 2013, the Donghuang II oil pipeline exploded in eastern China, killing 62 people and injuring 136. In 2009, a 50-foot-tall, high-pressure crystal production vessel in Belvidere, Illinois, exploded, injuring bystanders and killing a trucker. In 2000, a 30-inch natural gas pipeline owned by El Paso Natural Gas exploded killing 12 people. All these accidents were caused by pipe or structure failure due to undetected corrosion.
Standardizing the results
Currently, certified inspectors do corrosion detection. It is human driven, which means the results are inconsistent and subjective. What one certified inspector might classify as severe corrosion, another may call moderate. This basic human difference makes it difficult to standardize the results and decide where to spend money on repairs or recoating. Technology can solve this problem by unifying the way companies identify and classify corrosion. It’s unrealistic to have the same inspector look at every plant owned by a large corporation. Using computer vision, the results are based on the same data and easily standardized. This approach can create standard results at all company facilities.
Applying artificial intelligence and machine learning
In 2018, Infosys embarked on a proof of concept (PoC) with a mining industry client. The goal was to build an artificial intelligence and machine learning (AI-ML) system to improve the quality, consistency and predictability of corrosion detection. Infosys engineers used dense neural networks, hyper parameters, binary classification problems and convolution to come up with an AI prototype.
Currently, the preventive maintenance process involves only certified inspectors, who walk around the facility to evaluate corroded surfaces. Mining companies, electric and utilities, oil and gas, and chemical companies all have large steel structure that must be checked for corrosion. Depending on the size of the facility, this corrosion check could take weeks. The PoC set out to prove that machine learning computer vision techniques will deliver consistent, faster and cheaper corrosion detection on demand all year long.
The different levels of corrosion
The first step is to understand how corrosion occurs (Figure 1). There’s a protective coating on top of most external steel surfaces to prevent corrosion. Corrosion is called ‘coating loss’ because that is literally when it starts. Granules of dust and stains on the surface gradually break down the coating. As cracks develop, the coating will flake off, exposing the underlying surface. Coating loss is considered severe when that surface is exposed.
The proof of concept solves two classification problems
1. How can a machine see the corrosion in an image?
This is an issue of rust versus no rust. It’s done using a binary classification problem. The goal is to identify whether an image shows coating loss or coating normal. Annotated images marked as P1, P2 and P3 are classified as coating loss. Images classified as good are marked as coating normal.
2. Can a machine tell how severe the corrosion is?
This is a multiclass severity classification. The machine must not only identify corrosion, but also classify how severe it is.

Techniques applied to prove computer vision can identify and grade corrosion:
Machine learning engine
The machine learning engine is the foundation of the corrosion detection solution. There are various steps in a machine learning workflow, from data collection and preparation to data interpretation. Machine learning (both DNNs and convolutional neural networks) is widely used in deep learning, natural language processing and cognitive computing. In effect, this engine just keeps getting smarter and continuously learns to make better decisions on corrosion levels.
Image Annotations
Machine learning starts with the input dataset. It’s one of the most important parts of the process. Dataset preparation is especially complex when you have unstructured data, such as pictures. Images come in various sizes and resolutions. How do we use pictures to create a dataset? In this case, Infosys used a free tool called Labellmg to create 3,000 image annotations with a 70% percent test/train split.
Labellmg gives the user the ability to mark down portions of images and label them.
This tool is easy to setup on a local or cloud-based machine, the dataset doesn’t need to be taken out of the secure perimeter and it supports both Yolo and PascalVOC formats.
Feature Engineering
Feature engineering is the ability to select key aspects of the data to produce a structured result. The process puts data through several transformations to generate meaningful, uniform data to feed a machine learning engine. For this project, we’re using annotated image portions from a large image. Each annotated image will be classified as P1, P2, P3 or good. The classification label and annotated images are used to create the input vector. Technically, machine learning can begin working with a minimal dataset. But, the results from the machine learning model may not be accurate. The more inputs used, the better the results, and there is no limit to the number of inputs.
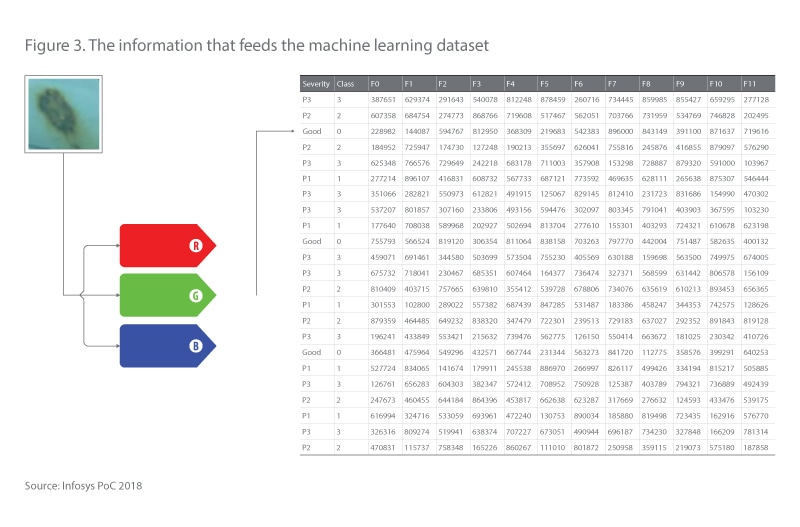
Figure 2 is an example of an annotated image. It’s composed of three color pixels encoded to represent the true image. When you’re looking at an input vector in a machine learning dataset, every line item represents an annotated image. The final step is data engineering (Figure 3). That’s when each annotated image goes through several transformation steps:
- Resize the image
- Extract the color channels
- Scale color codes
- Flatten the data
- Add them to the machine learning dataset

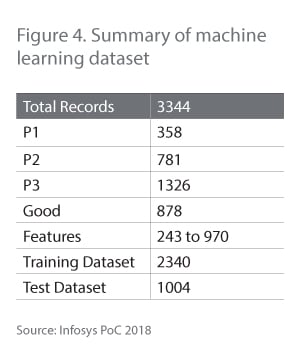
In the PoC, 2,340 records were used for training and 1,004 records were used for the test (Figure 4).
Applying convolutional neural networks
CNNs can produce more accurate computer vision results. Convolution is based on the way the human brain’s visual cortex is organized. Information is processed the same way the visual cortex records the data. In a DNN, the neuron in one layer receives input from all the neurons from the previous layer. Then, the output from a neuron is connected to all the neurons in the next layer and so on. In this case, the pixel from a picture is more connected to its adjacent pixels. Those pixels are more meaningful in producing a complete shape. Convolution identifies the edges and corners as smaller shapes. They are then interpreted together as larger or complete shapes. The number of convolutions varies depending on the shape being interpreted. That means convolution can identify a shape that is a combination of smaller shapes.
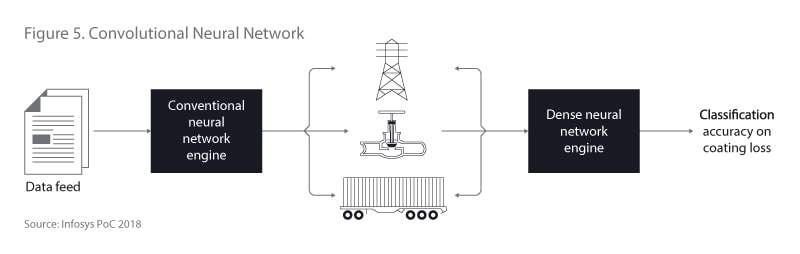
In the case of corrosion, the coating loss doesn’t have any shape or size. Flakes can come from coating loss, but they are all different shapes and sizes. CNN can be used to identify corrosion on a particular object, such as a pipeline, a transmission structure or a valve. Those objects have a definitive shape and size. The following workflow (Figure 5) can be used to more effectively identify the coating loss problem and reduce false positives.
Why are false positives so significant?
Facilities exposed to harsh environments and shaded areas can have several tones of red. Those red backgrounds can be mistaken for corrosion. False positives can result in wasted man hours attempting to repair equipment that is not corroded and can lead to mistrust of the system and a return to the status quo for maintenance and repair. The solution is to classify images through color segmentation.
Coating loss or rust exposure is generally a reddish color. The more the red matte tone is present on the rust, the more severe the coating loss. CNN can help avoid that problem by extracting and analyzing only the significant objects in the image.
The CNN to DNN workflow model can potentially reduce false positives. This technique has produced impressive results, the model identified 90% of coating loss and graded with 70% accuracy. The models were trained using DNNs with varying hyper parameters. There were some false positives, which can be reduced by using a combined CNN and DNN workflow approach. The models were developed based on 3,500 base annotations. Accuracy will improve over time as more annotations are added.

The next step
By combining all the techniques described here, Infosys proved that computer vision could effectively identify corrosion in a standardized manner (Figure 6). The model will need to be trained with additional images every few months, but the people using it won’t need much training at all. Users just have to be able to use a digital camera. There’s a simple user interface to upload pictures. After that, the system will automatically do the rest.
A drone can also be programmed to fly over the facility following a specific flight path and taking pictures along the way. In addition to detecting corrosion, this AI could be used to track other things such as algae on top of a water reservoir or inspect pipelines that are hundreds or even thousands of miles long. This PoC is just a glimpse at the future of computer vision and the many ways it can improve safety at companies and protect the environment around the world.


Chief marketing officers realize they need to change their approach to combat marketing ineffectiveness.
- 05 Jun, 2024

To maximize the benefits of AI technology, businesses must consider where to use it, and how it can augment or accelerate human processes.
- 16 Jan, 2024
- 15 min read

Ways in which businesses can use AI-driven tools, data, and analytics to increase organic revenue growth profitably.
- 16 Jan, 2024
- 8 min read