Artificial Intelligence




Revolutionizing Retail Unleashing the Power of Yolo for Product Detection
This whitepaper explores the advanced computer vision-based product detection system leveraging You Only Look Once (YOLO) algorithm. It delves into model development process encompassing data management, data collection & annotation, model engineering and reporting.
Insights
- In the dynamic world of retail, the ability to detect products accurately and efficiently is a game changer.
- This white paper examines You Only Look Once (YOLO) algorithm and provides reader with information on scalable model engineering pipeline using Infosys Video Analytics, part of Infosys Topaz, an enterprise ready solution the enables development of Vision AI models for product detection.
Introduction
Embarking on the creation of a computer vision-based object detection model involves seamlessly integrating diverse processes—meticulous data collection, annotation, and pivotal stages of model training, testing, reporting, and deployment. Our journey is powered by Yolo v4 for training, NVIDIA's A100 GPUs for advanced training, and Dataloop for annotation precision. Leveraging Infosys Video Analytics, an enterprise-ready solution, part of Infosys Topaz, our cutting-edge model engineering process ensures efficiency and accuracy. Join us as we delve into the intricacies of this transformative technological expedition, where every step, from data curation to deployment, contributes to the precision of our Vision AI models.
Deep Learning Model Engineering Capability Architecture view
Figure 1: Model Engineering Foundry (Source: Infosys Topaz COE Research)

Data Collection
Raw data collection should be strategically planned and activated based on business use case in the form of videos or images. Due consideration should be exercised as per various environment factors at play such as illumination, varied backgrounds, camera angle and orientation, distance of camera to object, occlusions and single or multi objects. Utilizing tools such as ring lights, rotating tables and photo box will help in simulating desired environment and expedite data collection process. The objective is to collect balanced dataset and the dataset should be meaningfully organized as per demand of the problem being addressed. While collecting data, a data scientist should consider data variety, balance, and quantity per classes.
Data Augmentation
For a good performing model, data variety is important. It is not always feasible to collect data manually. Hence synthesizing data with augmentation techniques such as flipping, cropping, rotation, adjusting image color variants, mosaic, mix-up etc. will add more variety to the training data set. It also helps to have a generalized model that does not overfit.
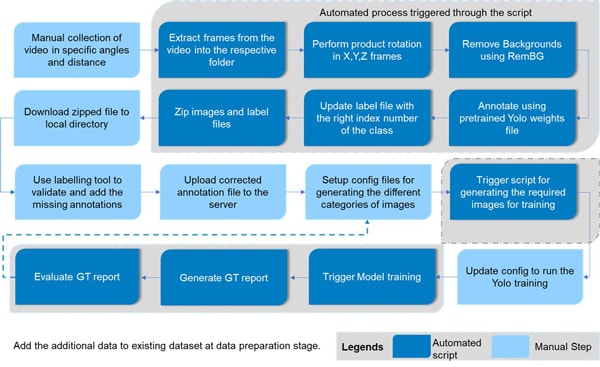
Data Annotation
This is one of the most important aspects of the data phase of Computer Vision System lifecycle. Labels should have scalable naming convention, considering variations. Annotated dataset should be structurally collected in folders and stored with adequate metadata. This metadata would help in categorizing the training dataset based on which Ground Truth Testing and its results can be analyzed. To improve training time, data scientists should also consider using auto-annotation to expedite annotation process.
Training
One should look for best suited pre-trained model for given business use case. In case of custom model training, one should consider using features like transfer learning and it must be an incremental iterative process. Modify training data according to prediction results and continue until it is tuned.
ML Frameworks
Machine learning frameworks allow data scientists and developers to build and deploy machine learning models faster and easier. Some of the popular ones are TensorFlow, pytorch, Sci-Kit learn, selection of framework should be based on need.
Ground Truth Validation
During every training iteration, Ground truth data segregation and its testing is critical. It helps to monitor and analyze performance of different versions or iterations of same model. Impact of training dataset on model performance can be analyzed with ground truth test results. This analysis helps in identifying corrective action on training dataset to make it balanced, thereby improving model performance.
Model Optimization / Export
A well-trained model should excel in performance; therefore, it is essential to adjust its hyperparameters to minimize the cost function. Further, it can be optimized using pruning, quantization (depending on requirement) and mixed precision techniques. We should be able to export a well-trained model with various formats depending on the given infrastructure and nonfunctional requirements such as latency and throughput.
Building a Deep Learning model for Retail Product Recognition
Let's delve into the key components of our product detection journey and the transformative impact it has on the retail industry.
A Comprehensive Dataset
Figure 2: Coverage of Dataset
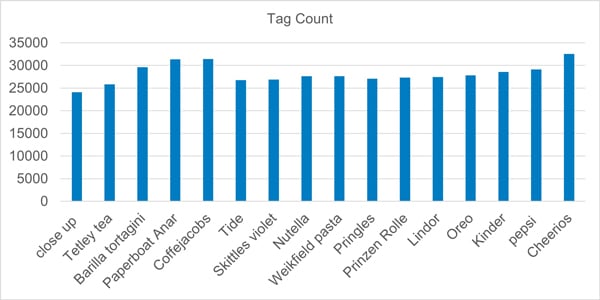
The foundation of our product detection system was a comprehensive and diverse dataset. Collecting data from different angles and distances ensured that crucial features of each product were effectively captured. We used automated tools to ensure consistency and accuracy during data collection. Additionally, we employed innovative techniques to generate synthetic data, further enriching our dataset. Our data annotation pipeline was designed for efficiency and scalability. We developed an auto-annotation pipeline that reduced manual annotation efforts to only 15% of the data. Remaining 85% was annotated automatically using a model trained on manually collected data. This accelerated the annotation process, allowing us to build a large-scale annotated dataset rapidly.
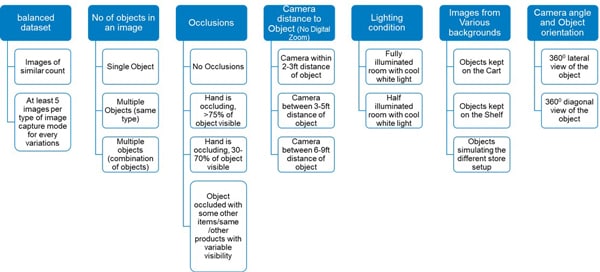
The dataset in focus is a meticulously curated, balanced collection of images that incorporates a multitude of variations to ensure the model's adaptability in various real-world scenarios.
Balanced Class Representation
The foundation of any effective object detection model lies in the balance of class representation within the training dataset. In this dataset, painstaking efforts were made to maintain equilibrium across all classes, ensuring that each object category is adequately represented. This balance helps the model avoid biases and perform well on all types of objects it may encounter.
Figure 3: Balance of Dataset
Variations in Object Presence
One crucial aspect of the dataset's richness is the variation in presence of objects. It encompasses a wide spectrum of scenarios, from single objects in isolation to multiple objects of same class coexisting within the same frame. This diversity is vital for training the model to recognize objects in both common and cluttered environments.
Figure 4: Single Object Image Capture Scenarios

Mix of Object Classes
In addition to varied object presence, this dataset goes a step further by introducing a combination of products from different classes placed together. This mimics real-world scenarios where products are often arranged in a mixed fashion, challenging the model to distinguish between multiple classes simultaneously.
Figure 5: Image Capture Scenarios with Multi Object Combination

Occlusion Challenges
Figure 6: Occlusion by Hand

The dataset does not shy away from real-world challenges. It includes images with varying degrees and types of occlusions. Occlusions can occur due to a variety of factors, including hands obstructing objects or other objects partially blocking the view. This diversity equips the model to handle situations where objects may not be fully visible.
Varying Object Distances
Objects in the dataset are captured at different distances, ranging from 2 feet to 9 feet. This variation in object distance is crucial for model to understand how an object's appearance changes as it moves farther away, which can be especially valuable for tasks like surveillance or robotics.
Figure 7: Image capture in variable distances

Diverse Lighting Conditions
Real-world lighting conditions can be highly variable, and this dataset reflects that reality. Images are captured in a range of lighting scenarios, from bright sunlight to dimly lit indoor spaces. Training model on such diverse conditions ensures it can perform effectively regardless of the lighting it encounters.
Background Variety
To add versatility to the model, the dataset includes images with different backgrounds. Objects are placed on various surfaces, such as carts, shop floors or even natural outdoor settings. This prepares the model to handle wide range of backgrounds it might encounter in practical applications.
Figure 8: Image capture in varying background

Multiple Viewing Angles
To ensure that the model captures features from all angles, objects in the dataset are photographed from various perspectives. This comprehensive 360-degree view is valuable for tasks like object recognition, where objects can appear in different orientations and angles in real-world situations.
Figure 9: Image capture in varying angles

Background images are images with no objects that are added to a dataset to reduce False Positives (FP).
Figure 10: Image with no products (false positives)

Best Practices for Efficient Training Data Compilation
Drawing from our experience, we offer following guidelines for effective assembly of training data to optimize model training.
- Class Image Quantity: It is advisable to include a minimum of 1500 images for each class.
- Instance Quantity: To ensure robust performance, aim for a minimum of 7500 labeled objects (instances) per class.
- Diverse Imagery: To meet demands of real-world applications, your dataset should encompass a spectrum of environmental conditions, such as different times of day, seasons, weather scenarios, lighting variations, diverse angles, and a variety of image sources, including web scraping, local acquisition, and various camera types.
- Consistent Labeling: Maintain uniformity in labeling by ensuring that all objects in all images are comprehensively and consistently labeled, avoiding partial or incomplete annotations.
- Precision in Labeling: Labels should precisely delineate each object, without any gaps or overlaps. Each object in an image should be paired with a corresponding label.
- Inclusion of Background Images: To reduce false positives, consider incorporating 0-10% background images into your dataset. For reference, the COCO dataset includes 1% background images, which do not require associated labels.
Data Annotation
Selection Of Data Annotation Tool:
In the intricate pipeline of creating a computer vision-based object detection model, a pivotal step is selection of the right data annotation tool. This decision holds paramount importance, particularly when dealing with a substantial volume of images, often numbering in tens of thousands. The choice of annotation tool is a multifaceted decision that can significantly impact efficiency, accuracy, and overall success of the project.
Several key considerations guided our selection process.
- A platform that could handle the sheer scale of our image dataset while maintaining organization and data integrity.
- Ability to seamlessly manage and navigate through a vast library of images.
- A tool that embraced latest AI advancements, allowing us to leverage cutting-edge technology for more precise and efficient annotations. This adaptability to evolving AI techniques was crucial in ensuring our model's competitiveness.
- Auto-annotation capabilities, which would not only accelerate the annotation process but also lay the groundwork for subsequent manual review.
- A comprehensive dashboard that could provide real-time insights into progress and performance of annotations and annotators was highly desirable.
- Cost-effectiveness was another essential factor, as we aimed to optimize our resource allocation without compromising quality of annotations. Thus, a detailed cost-benefit analysis was a pivotal component of our decision-making process.
After meticulous research, engaging with various vendors, and thorough evaluation of demonstrations, Dataloop platform emerged as our choice. It satisfied all our criteria by offering a robust infrastructure for data management, seamless integration of AI advancements, support for auto-annotation, insightful performance monitoring, review option and an economically viable solution.
To summarize, selecting the right data annotation platform was not merely a decision but a comprehensive process, driven by the necessity to manage an extensive image dataset efficiently and harness the power of AI advancements while ensuring cost-effectiveness. Dataloop's capabilities aligned perfectly with our project requirements, making it the ideal choice for our computer vision-based object detection model pipeline.
Figure 11: Data Capture, Annotation, Auto Annotation and Training Pipeline
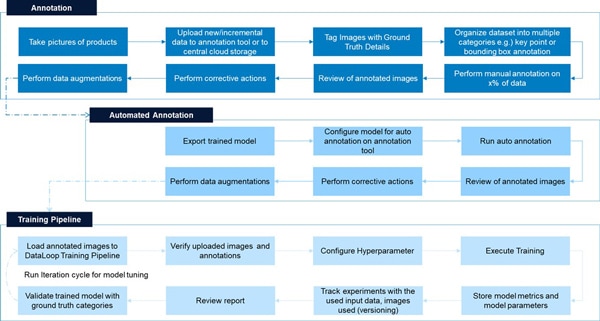
Manual Annotation
In this stage, 20% of the dataset is manually annotated by human annotators using a labeling platform such as Dataloop.
Manual annotation involves defining bounding boxes around objects of interest in images and assigning category labels.
Annotators also follow a naming convention that captures additional information about objects, such as occlusion types, distance, lighting conditions, camera angle, orientation, and other relevant attributes.
Initial Model Training
Train an initial object detection model with 20% manually annotated data. This model will learn to recognize and locate objects based on provided annotations.
Auto Annotation
Using the initial model, remaining 80% of dataset is auto annotated. Model predicts bounding boxes and category labels for objects in these images. These predictions are treated as auto-annotations.
Model-generated annotations may not be perfect, but they serve as a starting point for the next step. Auto-annotation significantly accelerates data annotation process and reduces manual effort to a considerable extent.
Manual Review for Correctness and Compactness
Human annotators play a crucial role in review process, meticulously inspecting both manual and auto-annotated data. Their primary focus is on precision - they verify accuracy of object labels and meticulously assess tightness of bounding boxes. These bounding boxes should encapsulate the entirety of the visible product, excluding any superfluous elements such as background, or overlapping features from neighboring products. If any inaccuracies are identified, annotators swiftly rectify them, ensuring that the annotations meet the highest standards of correctness & compactness. This meticulous review process guarantees that the dataset is of the utmost quality, setting the stage for a reliable and effective computer vision model.
Figure 12: Incorrect annotations and examples of Bounding Box not being compact
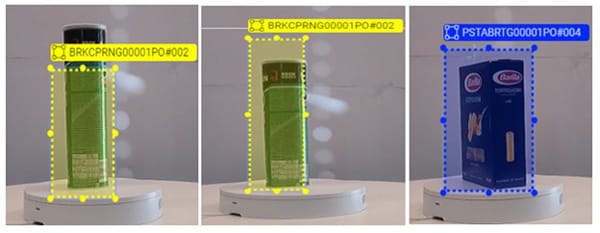
In the quest for greater efficiency & consistency, automation can be considered as a valuable ally. Automated scripts can be employed to expedite identification & rectification of incorrect annotations. These scripts can be designed to scan the dataset based on specific folder or file naming conventions, flagging annotations that deviate from expected standards. By automating this process, data review can be accelerated, and it can be executed with a high degree of accuracy, thereby reducing workload on human annotators, and enhancing overall reliability of dataset. Moreover, this combination of human expertise and automated support ensures that the final dataset is not only comprehensive but also thoroughly vetted, laying the groundwork for development of a dependable & effective computer vision model.
Naming Convention
Reviewers ensure that the naming convention, capturing various object attributes, is consistent across all annotations.
Naming conventions and annotations with detailed attributes are valuable for creating ground truth reports and analyzing model performance.
By associating object attributes with annotations, you can identify specific scenarios where model may be underperforming (e.g., certain lighting conditions, occlusion types or object distances).
This detailed information enables targeted improvements to the model for specific conditions or object categories.
Figure 13: Sample naming convention for annotation
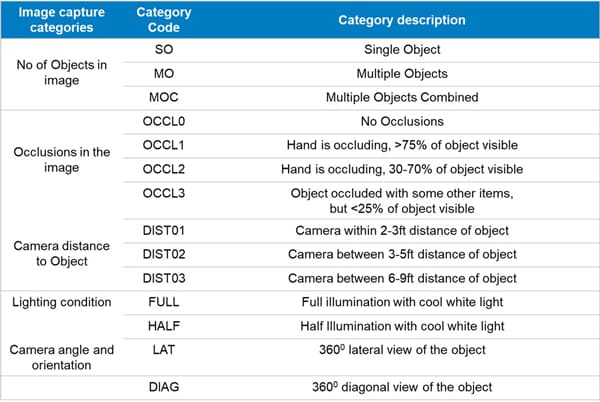
Figure 14: Example of Naming Standard
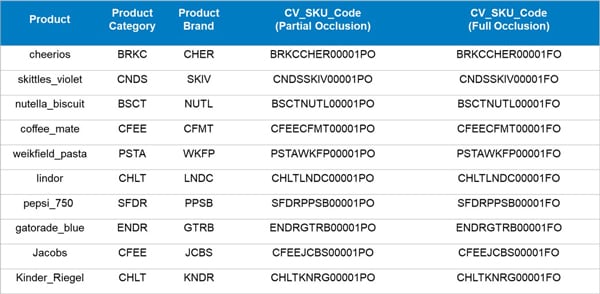
Figure 15: Naming sample in Data loop Platform

Synthetic Data
To bolster our dataset, we turned to synthetic data generation. We seamlessly integrated manually captured images by removing backgrounds with tools such as "rembg".
Figure 16: Synthetic Data Generation Process
With dynamic overlays of products on shelves in diverse configurations, we replicated the realism of manual data collection. This approach not only expanded our dataset exponentially, but also dramatically reduced time & effort needed for manual data preparation and annotation. By leveraging skills of 3D designers and experts in tools such as Unity and NVIDIA Omniverse, we have the potential to craft even more realistic synthetic data, further enhancing our model's robustness.
Figure 17: Examples of synthetic data generated by our process

In our pursuit of synthetic data generation, we considered various approaches:
Augmentation Libraries (Augmentations): We harnessed augmentation libraries such as Albumentations, Augmentor, and SOLT. Albumentations stood out for its special techniques like Mix-up and RICAP, in addition to fundamental augmentations like flips and brightness adjustments, aligning well with our requirements.
Background Removal (rembg): To eliminate backgrounds, we employed rembg, an image processing library. It proved highly effective, particularly with images shot against plain white backgrounds, allowing us to extract foreground objects for seamless overlay onto desired backgrounds with precise control over size, position, and shape.
Game Engines for Automation: Leveraging game development tools, we automated generation of diverse product image variations. This approach streamlined creation of images tailored to our specific use case.
NVIDIA Omniverse (3D Models): NVIDIA Omniverse offers a powerful option if you have 3D designers or product models. It enables the rapid generation of synthetic data, though it comes with a learning curve and the need for 3D expertise.
GenAI (Text-to-Image - Stable Diffusion and Dreamboothing): We explored GenAI's text-to-image generation techniques, including Stable Diffusion. Our experimentation with Dreamboothing, a fine-tuning of Stable Diffusion with custom text prompts, showed promise, but fell short of our satisfaction. We anticipate more accurate results in future releases of Stable Diffusion as technology evolves. These diverse approaches allowed us to tailor our synthetic data generation to our unique needs, striking a balance between ease of use, accuracy, and availability of expertise and resources.
Model Training
Selection Of Object Detection Model
In the initial phase of our project, selecting the right object detection model was of paramount importance. Training an object detection model from scratch proved to be a daunting task given our specific use case. We began our journey by evaluating a range of commonly known SOTA object detection models, including EfficientDet, DETR, SSD, YOLO, and Faster R-CNN. After comprehensive assessment, we made a deliberate choice and settled on YOLOv4 due to its outstanding performance in terms of accuracy, FPS, inference speed and other key factors.
For those facing a similar decision in selecting an object detection model, we recommend considering the following factors:
- Inference Speed: The speed at which the model can make predictions is crucial for real-time applications.
- Accuracy, Precision and Recall Requirements: Align model's performance metrics with specific needs of your project.
- Object Size: Some models may perform better with certain object sizes, so consider scale of the objects you intend to detect.
- Object Count: Evaluate model's suitability for simultaneously detecting single or multiple objects.
- Training Infrastructure: Assess hardware and computational resources required for training the model.
- Input Camera Resolution: Ensure that model is compatible with resolution of your input data.
- Availability of Training Dataset: Check availability and quality of training data relevant to your application.
- Licensing Agreements: Be mindful of licensing restrictions, especially if you plan to use the model in commercial applications.
- Model Size: Consider model size in terms of memory and storage requirements.
- Model Architecture: Understand model architecture and its suitability for your use case.
- Deployment Infrastructure: Think about intended deployment environment, whether it's a GPU, CPU, FPGA, mobile device, or edge device.
By carefully weighing these considerations, you can make an informed decision when selecting the most appropriate object detection model for your specific needs, ensuring success of your project.
Fine-Tuning with YOLO
Figure 18: YOLOV4 Training Process / Cycle
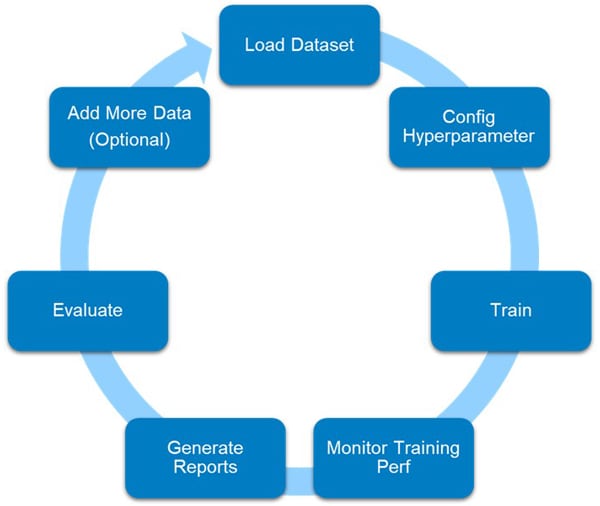
To develop a powerful product detection model, we utilized the pre-trained YOLOv4 as the starting point. We finetuned the model on our carefully annotated dataset, tailoring it to recognize a wide range of retail products accurately.
Iterative model training played a crucial role in achieving exceptional performance. Evaluating model after each iteration allowed us to identify areas of improvement. Subsequent iterations progressively refined the model's performance, honing it to perfection.
Over the course of 10 meticulous model training iterations, we systematically honed the model's performance, enhancing its capabilities for real-world retail scenarios.
Model Training Iterations
Our training journey was characterized by ten distinct iterations, each building upon the lessons and insights from the previous one. In each iteration, we undertook following key activities:
- Dataset Preparation: We began with an initial dataset comprising around 2,500 images per product, meticulously organized to encompass 5,000 instances for each class, distributed across the images.
- Initial Hyperparameters: For each iteration, we configured model with an initial set of hyperparameters, striving for a balance between precision and efficiency.
- Ground Truth Reports: At the conclusion of each iteration, we generated comprehensive ground truth reports. These reports played a pivotal role in our continuous improvement process. They provided crucial insights into the model's performance, particularly in terms of mean Average Precision (mAP) across identified ground truth categories.
- Performance Evaluation: These ground truth reports were meticulously reviewed, serving as a compass to identify areas where model needed enhancement.
- Data Augmentation for Underperforming Categories: In our quest for excellence, we focused on addressing performance of underperforming categories. Whenever these areas were identified, we systematically added more images to bolster the dataset.
- Scaling the Data: To ensure model's robustness, we progressively increased dataset size. By the end of our training journey, we had amassed a wealth of data, boasting approximately 5,000 images per class, with an impressive 7,500 instances of each class meticulously distributed across these images.
- Augmentation Techniques: Our training process was further enriched by a combination of internal and external data augmentation techniques, including angle, saturation, exposure, hue, blur, min crop, max crop, aspect, jitter, random, letterbox, gaussian noise, mix-up, mosaic, and mosaic bound. These augmentations collectively contributed to model's adaptability and resilience in diverse real-world scenarios. We also leveraged external augmentations such as cutout and warp to simulate occlusions and geometric transformations in our training data.
Key Model Training Parameters:
- Batch size = 64
- Image Resize – width = 736 px; Height = 416 px
- Momentum = 0.9
- Decay = 0.0005
- Learning rate = 0.001
- Burn in = 1000
- Maximum batches = 84000 (#total iterations)
- Policy = steps
- Steps = 67200,75600 (#80% and 90% of total iterations_
Leveraging our experience, we provide the following precise guidelines for optimizing your training settings:
- Start with Defaults: Initiate training using default settings to establish a performance baseline.
- Epochs: Begin with 250 epochs. Adjust if early overfitting occurs, extending training if overfitting is absent after 250 epochs.
- Image Size: YOLO typically uses a --img 640 resolution, but for datasets with numerous small objects, higher resolutions (e.g., --img 1280) are advantageous. Maintain consistent image resolutions for training, testing, and detection.
- Batch Size: Utilize the largest batch-size your hardware allows to avoid sub-optimal batch normalization statistics.
- Hyperparameters: Start with default hyperparameters before considering modifications. Automated hyperparameter optimization tools may be explored for advanced tuning.
High-Speed Training with NVIDIA A100 80 GB GPU
NVIDIA A100 80 GB GPU was a game-changer for us. Its remarkable speed and memory capacity allowed us to handle our large dataset of 7500 images per class with ease. The accelerated training process significantly reduced development time, enabling us to deploy our system quickly. We also enabled multi-GPU training.
We adhered to the recommended training approach, initially conducting approximately 1000 iterations on a single GPU before halting. Subsequently, we employed a partially trained model to resume training using multiple GPUs, up to four in total. In case of encountering 'NaN' values, it is advisable to reduce the learning rate, especially when utilizing four GPUs.
In our scenario, we had access to a GPU boasting 40 GB of RAM, and we were fortunate to have four GPUs at our disposal. For future endeavors involving training large transformer-based vision models, exploring options like "accelerate" and SLURM can prove highly beneficial for efficient multi-GPU training.
Evaluation with Ground Truth Reports
To assess the model's performance, we prepared our own ground truth reports using diverse test data. These test scenarios comprised various ground truth categories of the product, including different distances, angles, lighting conditions, occlusions, and backgrounds. This rigorous evaluation process ensured that our product detection system performed with remarkable accuracy and robustness.
Diverse Test Scenarios: Our evaluation was designed to challenge the boundaries of our product detection system. Test scenarios encompassed a rich array of variables, including:
- Ground Truth Categories: We considered a wide range of product categories, each with its unique set of characteristics.
- Different Distances: We evaluated model's performance at various distances from the products, spanning from 2 to 8 feet.
- Angles: The system's response to different angles of view was scrutinized, ensuring that it remained consistent, regardless of perspective.
- Lighting Conditions: We tested model's robustness under varying lighting conditions, from bright and well-lit environments to low-light settings.
- Occlusions: Partial or complete occlusions were introduced to assess model's ability to handle obscured objects.
- Backgrounds: Model's performance under different background conditions was a key focus, as the real world is replete with diverse environmental contexts.
The Dual-Pronged Reporting Approach
To comprehensively evaluate the model, we adopted a two-fold reporting strategy:
Figure 19: Ground Truth Report – Detailed Report

The detailed report provided an in-depth analysis of the model's performance. For each test image, it included:
- Predicted Annotation: This highlighted model's detections in each image.
- Ground Truth Annotation: This presented actual objects in the image.
- Image Category Information: Details such as presence of partial occlusions, distances, angles of capture, lighting conditions, and more were meticulously documented.
This level of granularity allowed us to gain insights into the model's response to each specific scenario, identifying areas for improvement.
Figure 20: Ground Truth Report – Class-wise Report
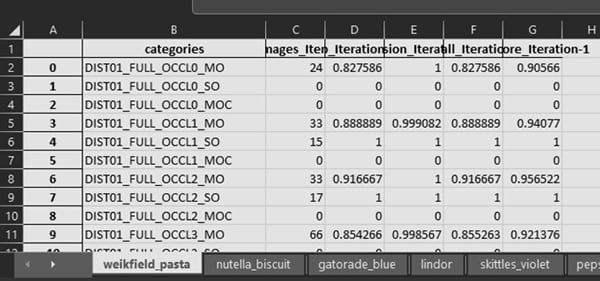
The class-wise report delved into performance of the model across various classes and categories of ground truth scenarios. It offered a breakdown of how the model fared under specific conditions, such as:
- Distances: Ranging from 2-4 feet, 4-6 feet and 6-8 feet.
- Occlusions: Assessing performance under partial or no occlusion.
- Lighting Conditions: Evaluating how the model responded in different lighting environments.
- Single or Multi-Object Scenarios: Capturing model's ability to detect combinations of objects.
- Background Conditions: Analyzing performance against various backgrounds.
The Power of Comprehensive Evaluation
This rigorous evaluation process served as a crucible for our product detection system. By subjecting the model to diverse and challenging test scenarios, we were able to validate its accuracy and robustness under real-world conditions. The insights gleaned from the detailed and class-wise reports provided a roadmap for improvements and fine-tuning.
High Throughput Deployment
To meet demands of real-world retail environments, we optimized and accelerated our model for high throughput and low latency. Achieving an impressive 30 FPS allowed our system to detect and recognize products in real-time, enhancing efficiency and customer experiences in retail stores.
The Need for Real-Time Detection: In retail scenarios, actions of picking up and putting back products can be lightning-fast. There is hardly any time for a camera frame to capture these movements, and factors such as motion blur further complicate the situation. To ensure accuracy of predictions, it is imperative that all frames are processed in real-time.
Optimization Strategies: Recognizing these challenges, we embarked on a quest to optimize our object detection system. Several strategies were explored, including pruning and quantization. Pruning involves reducing model size by eliminating unnecessary parameters, while quantization aims to reduce precision of the model's weights. These approaches have the potential to enhance model inference speed.
Challenges with Pruning and Quantization: Although pruning and quantization have been successful in certain applications, our experiments revealed that they were not the ideal solutions for our retail environment. These optimization techniques led to a noticeable drop in accuracy, which was a trade-off we couldn't afford in a retail setting where precision is crucial.
TensorRT Solution: After extensive experimentation, we discovered that the YOLOv4 model, when optimized and deployed using TensorRT (TensorRT is a high-performance deep learning inference optimizer and runtime from NVIDIA), provided us with desired accuracy and throughput. TensorRT allowed us to harness the full potential of our YOLOv4 model, optimizing it for real-time inference without compromising accuracy. The speed and precision achieved were precisely what we needed to meet the demanding requirements of real-world retail environments.
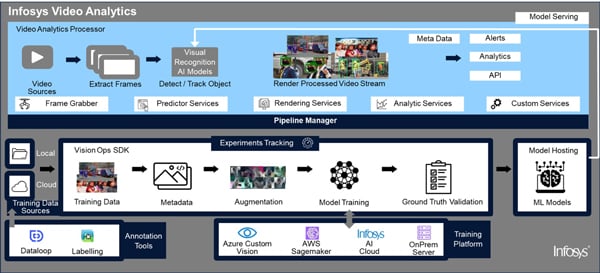
Infosys Video Analytics
Infosys Video Analytics, part of Infosys Topaz, is an AI-based solution that empowers businesses to leverage video / image content for actionable business insights. Packed with rich features to deliver vision-based use cases, it helps enterprises identify scenarios, actions, objects and much more within videos / image data sources. It comprises of the following modules:
Vision Analytics Processing: The module ingests feeds from motion, fixed cameras, and different vision-based sensors. Simultaneously, it also scans each frame of video, extracts information about events in the frame and persists this as metadata for downstream processing by enterprise systems. Infosys Video Analytics, part of Infosys Topaz, leverages NVIDIA Deepstream, a part of the NVIDIA Metropolis stack, to deliver some of the key AI processing capabilities on NVIDIA GPU platform.
Figure 21: Infosys Video Analytics - Vision Processing
Infosys Video Analytics Vision Ops SDK – provides ML Ops engineers a set of services to manage and drive the Model Engineering lifecycle across different training platforms effectively. It comprises of following key functions:
Figure 22: Infosys Video Analytics - Vision Ops management Lifecycle

Training Data
Annotated images are essential to begin model training process and generally available in COCO or YOLO format. Vision Ops SDK provides ability to acquire raw training data from various sources as local folder, S3 or from Annotation Tools such as Dataloop, LabelImg or LabelNow. It stores them in a standard manner for traceability.
Metadata extraction
Irrespective of source location, Vision Ops SDK takes care of generalizing structure and format of raw training data to be used for training. In addition, it extracts metadata information about annotated images from its nested folder structure, configuration file and from image file name. Metadata varies case to case depending on use case, but broadly it can contain location, region name, class, categories, occlusion types, lighting condition, date of collection, no of objects in an image, and more. The metadata extracted links the training data to specific model training iterations, and it is later utilized in reporting the model's performance.
Ground truth data segregation
The performance of a machine learning model is assessed by comparing its predictions with actual outcomes, a process known as Ground Truth Testing. Therefore, in each iteration, a subset of the training data is set aside for Ground Truth Validation to ensure that the model encounters unseen data during training.
Augmentation
Apart from raw training data, synthetically generated data speeds up model training process. Hence, Vision Ops provides flexibility to full or partial annotations. It also supports selective types of augmentation to be applied on a specific class. It is completely config driven. For instance,
[{“HorizontalFlip” : {“p”: 1},”Rotate” : {“limit” : 30, “p” : 1},”GaussianBlur” : {“p” : 1}}]
Training
When training data set is ready, local model training can be triggered. It also offers remote training with Azure Custom Vision. Idea behind training model on multiple platforms is to evaluate and pick best model for production. While model is being trained on given training dataset, training iteration is registered using mlflow.
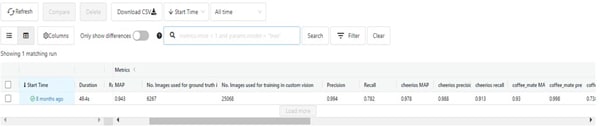
Ground truth validation and reports
When model training is completed, model will be deployed as an endpoint for Ground truth validation. Ground Truth Testing will be performed on segregated data using published model end point for current iteration of project.
As a last step, Ground Truth reports are generated i.e., with class-wise and summary reports.
Figure 23: Ground Truth Validation Report

Each training iteration is tracked in mlflow with unique identifier, and it stores all model artifacts for reference. The model files, model training data used, information about augmented data, model and class-wise metrics can be customized as well. Comparison between iterations or platforms can be performed to evaluate different models and choose right one for deployment.
Figure 24: ML Flow Tracking of Every Training Iteration
IVA Vision Ops SDK is configuration driven and extensible to support various platforms. Hence, it acts as an accelerator for model training.
Model validation pipeline is also available to do testing on different data sets against different models.
Conclusion
Our journey in developing a computer vision-based retail product detection system with YOLO has been transformative for the retail industry. By integrating data management, automated data collection and annotation, fine-tuned model engineering and iterative reporting, we created a robust and efficient system capable of recognizing products accurately and in real-time. With automation of Deep learning model training cycle by leveraging Infosys Video Analytics solution, part of Infosys Topaz, running on powerful NVIDIA A100 GPUs, we achieved faster training speeds to handle large scale datasets effectively, and this enables faster onboarding of new products.
With our product detection system in place, retailers can now embrace a new era of enhanced stock management, improved customer experiences and streamlined operations. The impact of our innovative approach is poised to revolutionize the retail landscape, unlocking new possibilities, and driving unprecedented success in the dynamic world of retail.
References







Subscribe
To keep yourself updated on the latest technology and industry trends subscribe to the Infosys Knowledge Institute's publications
Count me in!