Artificial Intelligence




RAG Challenges & Solutions
This whitepaper explores Retrieval-Augmented generation (RAG), a major development in natural language processing that produces extremely accurate and well-informed answers by fusing the advantages of generative and retrieval models.
Insights
- In the application of Large Language Models' (LLMs') capabilities, Retrieval-Augmented generation (RAG) have taken one of the prime spots to address drivers such as well-informed answers to user inquiries.
- This white paper examines RAG and provides reader with information on obstacles faced, the tactics used to get over them, and the most important lessons discovered along the way. The white paper also includes our experiences of creating and implementing a RAG system.
Introduction
RAG marks a major advancement in the application of Large Language Models' (LLMs') capabilities to improve information generating and retrieval procedures. RAG makes its main contribution by combining parametric information of the LLM with non-parametric knowledge to produce suitable answers to user inquiries.
Still, putting such systems into practice poses several significant obstacles:
| Lack of Content |
|
|---|---|
| Overlooked Top Ranked Documents |
|
| Contextual Limitations due to Consolidation Strategy |
|
| Failure to Extract |
|
| Incorrect Format |
|
| Inappropriate Specificity |
|
| Incomplete Answers |
|
| Response Latency |
|
Managing Multiple formats
RAG systems implementation presents a major problem in the efficient management of information spread over several formats. Real-world data distributions frequently occur across a variety of document formats, such as GitHub readme files, PowerPoint presentations, and PDFs. Every format adds special complexity in the form of different organizational techniques, components like tables and pictures, and systems. This calls for an architecture that can comprehend and produce answers by coherently processing textual, visual, and other kinds of input.
For example, if the primary use case for your application is text-based Q&A over PDFs, then you will handle text as normal; but, for images, you will create text descriptions and metadata at the preprocessing step and save the images for later usage. Depending on the type of image extracted, a combination of Large Language Models (LLMs) and Multimodal Language Models (MLLMs) are used to construct the answer during the inference phase. During this phase, the retrieval is mostly based on the text description and metadata for the images. This method has the benefit of having metadata from the information-dense image that helps tremendously with question answering and avoids the requirement to build a re-ranker to rank results from different modalities and to tune a new model for embedding images.
Managing tabular data, such CSV or XLS files, calls for a different approach. Text-to-SQL automates the conversion of plain language queries into SQL instructions, therefore bridging the gap between database systems and non-technical consumers. LLMs are used to enhance the Text-to-SQL process, which increases data processing efficiency and opens a range of use-cases including automated data analysis, intelligent database services, and quick query answers. With help of LLMs, SQL queries can be generated automatically from natural language. An approach, we have found helpful is to ask the LLMs to generate the query and then execute it with read-only access instead of directly giving the database details to LLMs which could result in unforeseen issues.
Database Options
There is obvious connectivity between Vector databases and LLMs. Effective operation of LLMs depends on embeddings, and vector databases provide the necessary structure for storing, managing, and fast retrieving these embeddings. The two functioning together ensures that AI systems access and process data at a speed never seen before in addition to understanding it. Examples of Vector databases include FAISS, Elasticsearch, PGVector, and Milvus. Every one of these has advantages and disadvantages of its own, and which is the ideal option for you will rely on your specific requirements. The four choices are briefly compared here:
FAISS
Facebook AI created the library FAISS (Facebook AI Similarity Search) to offer effective dense vector clustering and similarity search.
Simple to use and fast enough to handle millions of vectors in small-scale production scenarios are the scenarios where FAISS would be highly useful. By using quantization and GPUs and by lowering data dimensionality, their query performance can be raised. Key limitation includes its inability to scale.
Elasticsearch
Distributed and RESTful, Elasticsearch is an analytics and search engine with an expanding range of applications. Its versatility, scalability, and capacity to index various content kinds are well-known. The advantages of Elasticsearch are that it is a complete database, scalable, RESTful API with support for text and Vector search. Conventional keyword searches on blogs, logs, and documents work very well with it. Its fast full-text search-optimized inverted indexes significantly outperform vector databases made mainly for similarity search.
It works especially effectively when:
- Advanced text analytics and aggregations are required.
- Relevance of text search results is very important.
- Less than 1 terabytes of data; tolerable millisecond-range query latencies.
- A tried-and-true solution designed for massive text search is Elasticsearch. In use situations with a lot of text, it will beat vector databases.
PGVector
PGVector is an efficient high-dimensional vector storage and indexing PostgreSQL extension. The smooth connection with PostgreSQL is well-known and excels in the aspect that it allows SQL queries and integrates seamlessly with PostgreSQL.
With Postgres running underneath, PGVector immediately benefits from the following:
- Postgres offers several features appropriate for your vectors, including as row-level security, client library and Object-Relational Mapping (ORM) support, complete ACID compliance, and quick bulk updates and deletions (metadata updates happen in seconds).
- While several specialized Vector databases have not yet established their dependability, Postgres is a tried-and-tested database that can reduce operational complexity and the learning curve.
Milvus
Scalability and great performance are its well-known qualities and supports table-level partitions and several in-memory indexes. It is made especially to handle and analyze high-dimensional vector data, making it possible to save and retrieve vectors that stand for features taken from text, audio, and other sources. Milvus supports several indexing methods, such as Hierarchical Navigable Small World (HNSW) and Inverted File with Vocabulary Tree (IVF), to effectively arrange and retrieve vector data, hence improving search performance.
Scalability-first, Milvus can manage enormous amounts of high-dimensional data and facilitates distributed and parallel computing to guarantee excellent data retrieval performance.
Key Takeaways:
Though they provide excellent vector search performance and efficiency, FAISS and Milvus fall short of some of the capabilities of fully fledged databases such as Elasticsearch and PGVector. Before choosing a separate Vector database, you should consider the Vector search features of the databases you currently use (via PGVector and built-in vector fields, respectively). Your design can become simpler, and the operational complexity can be lowered with this method. Like always, the best option will rely on your exact requirements and situation.
Embedding
Consider data such as words, images, or sounds as distinct points in a large, multi-dimensional space. This space is constructed by an embedding model that processes data and assigns it a specific position based on its meaning and other key attributes. Words with similar meanings are positioned closer in this space, while those with different meanings are further apart.
This can be visualized as a conceptual map where proximate locations represent related ideas, like how close points in the embedding space contain similar data. These embeddings serve as a secret language that enables computers to comprehend the relationships between different data pieces.
Embeddings are generated from dedicated embedding models. They are trained on vast amounts of data, enabling them to understand intricate relationships within the data and convert it into this numerical language.
To select the most suitable embedding model for your Retrieval Augmented Generation (RAG) application, we suggest beginning with the MTEB Leaderboard on Hugging Face. This leaderboard offers current information on various text embedding models, including both open-source and proprietary ones. It also includes benchmarks that evaluate each model's performance on different tasks such as retrieval and summarization.
Domain-Specific Embedding Adaptors in Large Language Models (LLMs) are a technique used to fine-tune the embeddings of an LLM to better suit a specific domain or task. It addresses this issue by allowing the embeddings of the LLM to be fine-tuned for a specific domain or task. This involves training a small, additional model that adapts the embeddings of the LLM to better suit the specific domain or task. This can lead to significant improvements in the performance of the LLM on that domain or task, without requiring the entire LLM to be retrained.
However, it is crucial to remember that these benchmarks are self-reported and may not accurately represent how the models will perform on your specific data. Moreover, some models might have been trained on the MTEB datasets, which are publicly accessible. Hence, it is advisable to assess the models on your own dataset before making a final decision.
Since RAG relies on retrieving relevant information, we will focus on the leaderboard columns that best reflect this ability. Here is a breakdown of what we will be looking at:
- Retrieval Average: This score shows the average performance of the model across multiple datasets, using a metric called NDCG@K. Think of NDCG to measure how well a model ranks relevant information high in its search results. Higher scores indicate better retrieval models.
- Model Size: This simply tells you how much storage space the model needs. While bigger models often perform better at retrieval tasks, they also take longer to process information (latency). This trade-off between performance and speed is especially crucial when deploying the model in real-world applications.
- Max Tokens: This tells you the maximum number of words the model can handle in a single embedding. We typically would not use more than one hundred words (around a paragraph) for an embedding, so even models with a 512 token limit should be sufficient.
- Embedding Dimensions: This refers to the length of the numerical code used to represent the information. Smaller codes are faster to process and take less storage, but they might miss some of the complexity within the data. Here, we want to find a sweet spot between capturing detail and running efficiently.
The top models on the leaderboard offer a variety of options, with some being small and open source, while others are large and proprietary. By comparing these factors, we can identify the best embedding model for our specific dataset and needs. Here are some of the best performing models.
- GIST-small-Embedding-v0: The model is fine-tuned on top of the BAAI/bge-small-en-v1.5 (33.4M Parameters)
- Voyage-lite-02-instruct: VoyageAI’s one of the latest proprietary embedding models (1220M parameters)
- UAE-Large-V1: A small open-source embedding model (335M parameters)
A careful balance across parameters, domain coverage and performance benchmarks will help you to arrive at a final pick best suited for your RAG application.
Caching
Modern microservices often include cache, which enables sub-millisecond fast access to data from slower databases. Real-time application answers are made easier by this, which is an essential need for many companies. Still, the issue is more difficult in the setting of RAG applications for several reasons:
- There is considerable latency in LLM calls, whether they are hosted in-house or through third-party services like Azure OpenAI.
- These calls often involve costs, as most cloud services charge per transaction.
- Standard caching solutions are not suitable, as they cannot differentiate between similar but distinct queries, such as
"List down the top 10 best practices in Spring Boot application"
"List down the top 15 best practices in Spring Boot application"
As such, we advise against traditional caching and towards Semantic caching solutions. Based on the semantics or context within the queries themselves, semantic caching records queries and their results in a data store.
Semantic caching stores and rapidly retrieves pre-processed data and answers, hence optimizing response time. Two crucial locations in a RAG system can have it applied to increase speed:
- Information Retrieval: By preprocessing and storing often accessible data and knowledge sources, semantic caching helps expedite the creation of enriched prompts.
- LLM Calls: Faster response generation is achieved by semantic caching's ability to rapidly obtain pre-processed data and responses from prior encounters.
The LLM community has given huge acceptance for GPTCache and it looks like a viable choice. It makes cache data available even after application restarts possible by enabling it to be kept in a database (RDBMS + Vector). Returned cache hits should be returned if the similarity is more than 95% certain.
Model Integration
One of the key components of RAG systems is Language Model as it is the one responsible for generation and imparting coherence to the answer, hence choosing the right model can be a taxing task and with ever evolving space like this we get to see exciting breakthroughs in open source as well as proprietary models. Each model comes with a cost factor, latency, and its own security risks.
Open-Source Models: Free Access, Collaborative Power
Open-source models offer a compelling value proposition. They are readily available, often with well-documented code and active communities. This fosters collaboration, leading to continuous improvement and innovation. Additionally, the absence of licensing fees makes them a cost-effective option(mostly).
Advantages:
- License Cost: Freely available with no licensing fees
- Transparency: Access to code allows for customization and understanding
- Community-driven: Benefit from ongoing research and improvements
- Dataset: The kind of data the models are trained is known for any analysis or explainability
Disadvantages:
- Limited Support: May require in-house expertise for troubleshooting and optimization.
- Cost: Hosting requires significant investment either in terms of hardware or cloud costs.
- Performance: May not always match the capabilities of proprietary models.
- Security/Filters: Raw models mostly require extra layer of pre-processing and post-processing to filter out the queries and responses which are not in line with values.
- Scalability: Managing large-scale deployments can be resource intensive.
Self-Hosting Open-Source Models: Layers of Consideration
While self-hosting open-source models is cost-effective, it requires additional layers of implementation:
- Infrastructure: Servers and computational resources to run the model
- Maintenance: Ongoing updates and bug fixes
- Expertise: Technical knowledge to manage and optimize the model
- Responsible: The kind of responses can be very raw and usually the models come with no security layer hence implementation of Responsible-AI layer before exposure to end user
Proprietary Models: Performance and Ease of Use
Proprietary models are commercially licensed solutions developed by private companies. They often boast cutting-edge performance and are optimized for specific tasks. Additionally, vendors typically provide support services, simplifying deployment and troubleshooting.
Advantages:
- Performance: May offer superior retrieval accuracy compared to open-source models.
- Ease of Use: Streamlined integration with pre-built APIs and support services enabling faster go to market.
- Scalability: Designed for high-volume deployments with robust infrastructure.
- Security/Filters: Usually comes with wide range of guardrails and security filters along with configurations to tweak around.
- Cost: Most of the services are pay-as-go hence for applications with less usage pattern the cost comes out to be less than even hosting a VM in cloud.
Disadvantages:
- License Cost: Licensing fees can be significant, especially for large-scale deployments.
- Finetuning: In case of domain specific requirements, fine-tuning options are limited.
- Training Data: Datasets used to train the models are not published which can be make it difficult to understand the possible bias and explainability of the responses.
- Black Box: Limited access to the underlying code hinders customization.
- Vendor Lock-in: Dependence on a single vendor reduces flexibility.
Choosing the Right Model: It is All About Your Needs
The optimal model choice hinges on your specific needs. Here is a breakdown to help you decide:
- Cost: The transaction cost for hosted models begins at $0.0002 per transaction. On the other hand, open-source models require hosting on a GPU system, which typically starts at around $1500 per month. Therefore, it is recommended to compare the costs of these two options to make an informed decision. If the usage is not particularly high, cloud-hosted models can lead to cost savings in a relatively short timeframe.
- Performance: If retrieval accuracy is paramount, proprietary models might be worth the investment.
- Expertise: If your team lacks in-house expertise, the support offered by proprietary models can be valuable.
- Customization: If you need to modify the model's behavior, open-source options provide greater flexibility.
Our ideology is to have maximum flexibility in the solution hence the solution should be designed with adaptors to a single specification like OpenAI specification and having a wrapper layer in between model and application to abstract out the model specifications enabling solutions compatibility with all models. This can work very well where teams start small to establish the use case with hosted models and for scaling up if they want to switch to in-house model, it can be done without much of changes or breakages.
Frameworks
RAG applications based on Generative AI are now mostly written in Python and are implemented by a number of frameworks, the best two being Langchain and LlamaIndex.
This two are mostly different in that LlamaIndex is a search and retrieval-focused specialized framework for RAG applications. By comparison, Langchain is a multifunctional LLM framework and provides comprehensive set of features in building applications powered by LLMs that go beyond RAG. But LlamaIndex is designed expressly to build search and retrieval apps. It provides a simple interface for searching LLMs and getting relevant documents. Because LlamaIndex processes data more efficiently than Langchain does, it is the best option for applications that need to handle a lot of data.
An ideal option for a general-purpose application needing extension and flexibility is Langchain. On the other hand, LlamaIndex is the better search and retrieval program if simplicity and effectiveness are your top priorities. Langchain shines, nevertheless, in the field of feature implementation speed. By doing such, it has brought in a considerable degree of complexity that can be hard to comprehend.
Haystack and Semantic Kernel are two frameworks that exhibit considerable promise even if they may not have as many functionalities as Langchain does right now. Enterprise AI app development employing RAG requires optimal Retrieval Augmentation evaluation, which Haystack provides together with configurable pipelines and a single interface for data storage. On the other hand, Semantic Kernel is regarded as a lightweight, well-designed solution that works well with other Microsoft products and services.
Foundational Tuning of Ingestion
Indexing: Arranging data for fast and effective retrieval is known as indexing. Within a RAG system, this might entail compiling an index of every document in the database together with metadata (like length, word count, etc.) for each document. After then, one may rapidly locate documents related to a certain query using this index. Selection of a suitable indexing method affects application speed and accuracy and is mostly determined by the application's domain and demand.
Managing the Context Memory: This is about maximizing the quantity of historical background that the system can remember. Context is essential to comprehending assertions in a conversation. To offer pertinent answers or analysis, the system must retain past conversations or data. Finding the right amount and effective way to store historical context is the problem. Importantly, the token limit must be considered.
Query Expansion: This situation is perfect for the query expansion method, which improves the user's original search to produce a more thorough and educational one. Further pertinent documents will then be retrieved from the vector database by this newly created query.
- Multi Query Retrieval: The Multi-query retriever from LangChain generates several queries from different viewpoints based on a single user input query, hence achieving query expansion. For every query it retrieves a set of pertinent documents, and it takes the unique union of all queries. Here, several search queries are generated using an LLM. Subsequently, the results of these search queries can be processed all together. When one question might depend on several sub-questions, this is especially helpful.
- LangChain's HyDE: HyDE (Hypothetical Document Embeddings) retriever embeds and uses fictitious documents it generates for an incoming query. The idea is that these fake documents might be closer to the intended source documents than the actual inquiry.
Performance benchmarks
Without talking about performance and cost, a discussion of Retrieval-Augmented Generation (RAG) systems would not be complete.
For reference, consider the following code snippet, which is typical in a Langchain-based RAG application. This code interacts with the LLM in a conversational manner, sending the chat history along with the user's query. This approach ensures the LLM is informed about the session history, enabling it to provide a more contextually appropriate response.

Our implemented cost module, which calculates the cost for each invocation, revealed that we were being billed twice. Upon reviewing the Langchain code from GitHub, we discovered that in the ConversationalRetrievalChain, the user's question is first rephrased before being answered. Although there is an open feature request to make this configurable, it has not yet been implemented. This was the cause of both the delay and the double billing for LLM invocation.
To address this issue, we altered our logic to use another Langchain method. In this method, we send the chat history along with the prompt and fine-tune the prompt to ensure the LLM comprehends the chat history. The revised code resulted in a noticeable improvement in response time and normalized the cost.

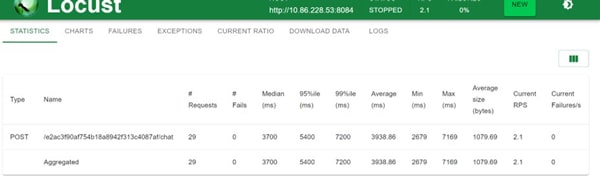
Next, we wanted to determine the maximum number of concurrent users our RAG application could handle. We used Locust for performance load testing, starting with a peak concurrency of five users and a ramp-up rate of five users per second. The results showed that each request took less than 15 seconds on average to execute, with no failures.
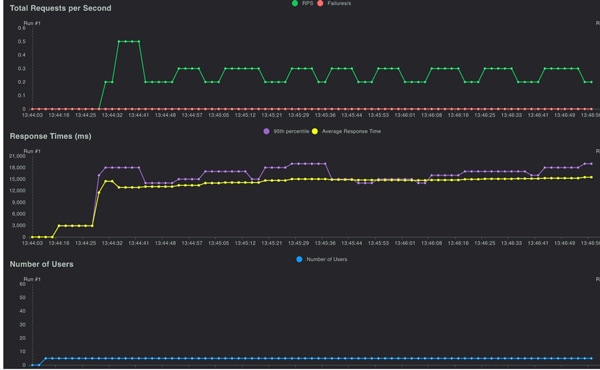
To further validate, we increased the number of users to fifty and the ramp-up rate to fifty. The results were chaotic, with an average execution time of 180 seconds. We also inferred that the requests were being processed sequentially, not in parallel.

To ensure the issue was not with Azure OpenAI, we directly invoked their service, which confirmed that Azure OpenAI could easily handle 150 requests.

Upon further examination of the Langchain code, we discovered that the LLM invocation was a blocking call. All the examples we found online used the same code as above. However, we found an asynchronous LLM invocation in the Langchain code, which is not commonly used. We rewrote the code to make all invocations asynchronous in Python and used Langchain’ s ainvoke.

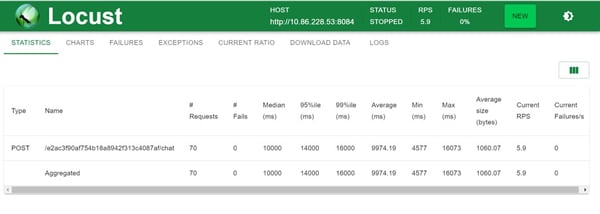
After rerunning the load testing with Locust, the results were in line with typical Microservices. We observed that requests were being processed concurrently, which was not the case previously. The average timings were 4 seconds for five users per second and around 9 seconds for fifty concurrent users. This is expected, given the CPU-intensive tasks we perform and the fact that our application runs on commodity hardware.
Configurability
Configuration as Code (CaC) is a DevSecOps methodology where configuration files, which outline the resources and settings for software and infrastructure, are managed as code files. This implies they are stored in a version control system, and modifications to them undergo review and testing, like application code changes. For Retrieval-Augmented Generation (RAG) applications, this practice needs to be elevated due to the high degree of variability.
New embedding models are being released daily, and given the field's infancy, significant advancements are being made. The available target hardware cannot be predetermined. Depending on hardware capabilities, certain features and models may need to be disabled.
This approach should also be applied to dockerization to prevent the docker image size from exceeding 10 GB. Furthermore, in the target environment, it could be an air-gapped environment, making Hugging Face potentially inaccessible.
The recommendation is to cache all models used in the RAG lifecycle in an object storage and download the respective models during the application's bootstrap process.
Key Lessons Learned
Improving Accuracy with ReRanking After the initial retrieval of documents, a more complex model, known as a cross-encoder, is used to re-rank the top retrieved documents. The cross-encoder takes both the query and each document as input and outputs a score indicating how relevant the document is to the query. The documents are then re-ranked based on these scores. This can often improve the quality of the top-ranked documents, as the cross-encoder can consider more complex interactions between the query and the document than the initial retrieval model. Reranking significantly enhances the precision of RAG implementation. While this approach is highly effective, it is also CPU-intensive and introduces significant latency, which could affect the application's usability. The bge-reranker-base model has shown substantial improvement in our tests.
Feedback Mechanism
The introduction of RAGA (Retrieval-Augmented Generation with Actions) enhances the existing structure by adding an action-execution step. This means it doesn't just generate responses, but also carries out actions based on the information produced. This is a significant advancement towards making AI systems more interactive and autonomous.
- Action Stage: This is the novel component in RAGA. After generating responses, this stage is tasked with performing suitable actions derived from the insights of the generated responses.
- Action Determination: Depending on the generated response, the system decides the action to be executed. This could be established through preset rules or learned via reinforcement learning techniques over time.
- Action Execution: Once the action is decided, RAGA carries it out. This could vary from sending an alert, modifying a system setting, interacting with other software or hardware components, to even making decisions that influence a wider workflow.
- Feedback Loop: After the action, any feedback is gathered to fine-tune the action-determination process. This loop aids in enhancing the precision and relevance of actions over time. It is crucial to implement a feedback mechanism allowing users to report subpar responses, and then establish a system to address these issues manually or automatically. Accepting that perfection will not be achieved on day one and gathering necessary information for future improvement is a proactive approach that paves the way for enhancements.
Storing Raw Files
Preserve the original files uploaded by users in an object storage. There will be numerous occasions where users might interpret the Large Language Model's (LLM's) response as incorrect. However, in about 70% of these cases, the perceived error could be attributed to outdated or incorrect documentation that requires updating. If a user uploads a file that is either incorrect or contains sensitive information and needs to be deleted, the corresponding vector entries can be removed using this original file as a reference.
Furthermore, one constant with Retrieval-Augmented Generation (RAG) applications is the ongoing development of enhancements to improve overall performance. Whenever improvements are made in the data ingestion stage or if a chunking strategy is implemented, the original raw file will be necessary to re-ingest the document.
To elaborate, the raw files are crucial for maintaining the integrity of the system. They serve as a reference point for any changes or updates that need to be made. For instance, if a document is found to contain outdated or incorrect information, having the original file allows for accurate updates to be made. Similarly, if a file containing sensitive information is uploaded, having the original file allows for the precise removal of any corresponding entries in the system.
In terms of system improvements, the raw files are also essential. As RAG applications continue to evolve, new strategies for data ingestion or chunking may be developed. These strategies may require re-ingesting the original documents to ensure they are processed correctly under the new system. Therefore, maintaining the original raw files is a crucial part of managing and improving RAG applications.
Retrieval Tuning
Retrieval Tuning is a technique used in the context of Retrieval-Augmented Generation (RAG) models and Large Language Models (LLMs) to improve the performance of information retrieval and question answering systems.
RAG models are a type of transformer-based model that combines the strengths of pre-trained language models with the ability to retrieve and use external documents to generate responses. Retrieval Tuning involves fine-tuning the retrieval component of the RAG model to better select relevant documents for a given input. This is typically done by training the retrieval component on a dataset where the correct documents to retrieve for each input are known. Techniques might include sentence window retrieval (retrieving a window of sentences around the target sentence) and auto-merging retrieval (automatically merging retrieved documents to form a single context).
The goal of Retrieval Tuning is to improve the quality of the documents retrieved by the RAG model, which in turn can improve the quality of the responses generated by the model. This can be particularly important for tasks like question answering, where the ability to retrieve and use relevant external information can significantly improve the model's performance.
Guardrails
Compliance with privacy laws, ethical guidelines, and the implementation of strong security protocols are essential in preserving the reliability and credibility of Retrieval-Augmented Generation (RAG) applications. It is essential to control the input to the LLM and the output received from it. In enterprise applications, these intelligent RAG applications powered by large language models (LLMs) should always be accurate, appropriate, on-topic, and secure. NVIDIA’S NeMo Guardrails allows developers to align LLM-powered apps to ensure they are safe and remain within the company’s areas of expertise. Its key features are.
- Programmable Guardrails: Define the behavior of your LLM, guiding conversation and preventing discussions on unwanted topics.
- Seamless Integration: Easily connect your LLM to other services and tools (e.g., LangChain), enhancing its capabilities.
- Customization with Colang: A specialized modeling language, Colang, that allows you to define and control the behavior of your LLM-based conversational system.
RAG Result Evaluation
Evaluation is crucial in determining response accuracy. Choose a model-based evaluation to quantify the performance of your LLM applications on factors such as faithfulness, answer relevancy, contextual recall, etc. DeepEval, developed by Confident AI, is an open-source framework designed for model-based evaluation. It allows you to assess your Large Language Model (LLM) applications by quantifying their performance in areas like faithfulness, answer relevancy, contextual recall, and more as depicted below.
| G-Eval | Employs a chain-of-thoughts (CoT) approach to assess LLM outputs according to any custom criteria. and its accuracy akin to human judgment. |
|---|---|
| Summarization | Ability of an LLM to generate a concise and accurate summary of a given text. |
| Faithfulness | Indicates if the final response is firmly rooted in the retrieved context. Helps to understand if the system might be creating its own information or overly depending on its pre-training data. |
| Answer Relevancy | Validates if the response is genuinely pertinent to the initial query and helps to idenfity if it has misinterpreted the question or deviated from the intended subject. |
| Contextual Relevancy | Determines how pertinent each retrieved context is to the initial query and helps in spotting potential problems in the retrieval mechanism. |
| Contextual Precision (Groundedness) | Indicates how accurately LLM retrieves and uses information from the given context to generate a response. |
| Contextual Recall | Ability of an LLM to retrieve and use all relevant information from the given context to generate a response. |
| Hallucination | This refers to the generation of information by an LLM that is not supported by the given context or data. It can occur when the LLM relies too heavily on its pre-training data or when there is too much conflicting information or noise in the context. |
| Toxicity | Indicates the generation of harmful or offensive content by an LLM. It can occur due to biases in the training data or the LLM's inability to understand the social and cultural implications of its responses. |
| Bias | This refers to the presence of systematic errors or prejudices in the LLM's responses. It can occur due to biases in the training data or the LLM's inability to accurately represent diverse perspectives and experiences. |
Prompt Engineering
Prompt Engineering is a widely discussed concept in GenAI implementation. The success or failure of such implementation heavily depends on the implementation of the Prompt and how well the LLM understands it. Regrettably, developing LLM-based applications today involves adjusting and modifying prompts.
Transitioning from writing code in a programming language that the computer follows precisely to writing vague natural language instructions that are imperfectly followed does not seem like progress.
DSPy is a state-of-the-art framework developed by the Stanford NLP group, designed to algorithmically optimize language model (LM) prompts. Its approach revolutionizes the prompt engineering cycle, transforming it from a typically manual, artisanal process into a structured, well-defined machine learning workflow. This includes preparing datasets, defining the model, training, evaluating, and testing. It enhances the performance of AI-driven systems by orchestrating Large Language Model (LLM) calls with other computational tools, targeting downstream task metrics. Unlike conventional "prompt engineering," it automates prompt tuning by converting user-defined natural language signatures into comprehensive instructions and few-shot examples.
DSPy has found extensive application across various language model tasks such as fine-tuning, in-context learning, information extraction, self-refinement, and many more. This automated approach surpasses standard few-shot prompting with human-written demonstrations by up to 46% for GPT-3.5 and 65% for Llama2-13b-chat on natural language tasks like multi-hop RAG and math benchmarks like GSM8K.
Conclusion
The Retrieval-Augmented Generation (RAG) architectural design pattern in generative AI and contemporary applications has demonstrated advantages in providing more pertinent and current responses to user inquiries.
However, a sturdy modern application demands more than a basic RAG implementation. To improve applications' user engagement, aspects such as customization, historical context, and swift response times are considerations that AI engineers and developers should consider as early as the proof-of-concept or demonstration stage of development.
References
- https://stackoverflow.com/questions/76990736/differences-between-langchain-llamaindex
- https://qdrant.tech/documentation/frameworks/dspy/
- https://blogs.nvidia.com/blog/ai-chatbot-guardrails-nemo/
- https://github.com/zilliztech/GPTCache
- https://docs.confident-ai.com/
- https://cloud.google.com/products/calculator?dl=CiRkYzc3OWJhMy04NzZhLTQ2ZTItYmI1YS1hNzg5MzIxMzk1NGUQEBokMERFRjkxMDAtMjg4Qy00NTc0LTg0OUMtQjA0RTE5MjExQjBB
- https://arxiv.org/html/2401.05856v1
- https://developer.nvidia.com/blog/an-easy-introduction-to-multimodal-retrieval-augmented-generation/







Subscribe
To keep yourself updated on the latest technology and industry trends subscribe to the Infosys Knowledge Institute's publications
Count me in!