Artificial Intelligence




GPT the Untamed Wild LLM: Fundamental Limitations and Solutions for Enterprise Implementation
This whitepaper explores generative pretrained transformer (GPT) large language model (LLM) capabilities in context of its fundamental limitations leading to restricted enterprise applicability and how these can be addressed.
Insights
- As part of enterprise requirements, there is a need to have a powerful tool like GPT LLM which has capabilities to address a wide range of tasks across myriad domains of expertise.
- This white paper examines generative pretrained transformer LLM technical limitations and provides reader with information on how these can be effectively addressed. The white paper also includes the reference implementation views.
Introduction
A generative pretrained transformer LLM is a very powerful tool with a wide span of capabilities but restricted in practical applicability because of its fundamental limitations. It is intriguing to observe all the myriads of things a LLM can do in a human-like way generating novel contents including texts, images, audios, videos and more. But irrespective of how wide spanning the capabilities are, unless the intended business use case is served rightly, it is not fit for enterprise use. Essentially it can be termed a wild LLM, just like a wild horse, having lots of power but not fit for specific purposes unless tamed well.
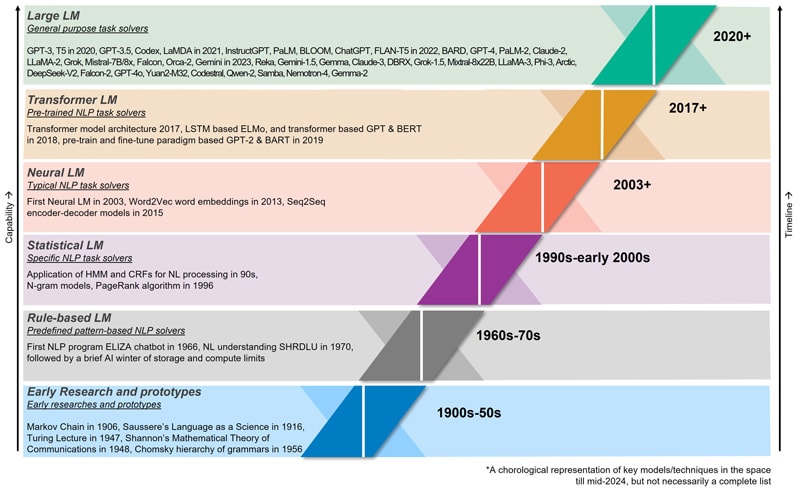
Before we delve deep into the wild nature of generative pretrained models (GPTs), let us get some understanding on the Language Models (LM) space which has now led to the GPTs of the world. The language model space has over 100 years of history, from early Markov Model research in 1906, to first NLP application ELIZA in 1966, and the pathbreaking Transformer model architecture in 2017 leading up to LLMs of the world today. It is interesting to note that there was a brief AI winter from mid-1970s owing primarily to technology limitations in storage & compute, funding shortage, and fragmented research. Language modeling space witnessed a paradigm shift from 2020 onwards starting with GPT-3, the GenAI democratizing ChatGPT in 2022, and release of increasingly more powerful LLMs in the following years. Currently there is renewed focus on the implementation aspects of LLMs including deployment frameworks, specialized agents, safety guardrails, domain-specific & narrow models, fine-tuning & RAG variants, and more.
Figure 1. A timeline view of evolution of language models leading up to GPT LLMs of the world
Fundamental Limitations of GPT LLMs
A generative transformer model, pretrained on humongous amounts of generic world data, is like a wild horse – very powerful but not tamed. It is fascinating to observe all the myriads of things it does in a human-like way generating novel contents from question responses, story text, images, to videos and more. This very true with the recent models like GPT-4, Calude-3, Gemini 1.5, Llama-3, and any other recent GPT LLM. Here one point to note is that, while industrially GPT is a brand name used by OpenAI for it models but in a broader academic context it can refer to all transformer-based models which are pre-trained and generative in nature.
A typical characteristic of these high profile GPT LLMs is its generalization or the capability to address a wide range of tasks across myriad domains of expertise. This very capability, which gives it a human-like novel response character, is becoming the key reason which limits the direct practical application in enterprises. To put in a nutshell, while these models perform increasingly well in academia and generic tasks, these are not fit for purpose in practical enterprise business scenarios.
When it comes to enterprise implementation, the requirement will always be specific and contextual to certain scope. Like responding to customer questions in virtual assistants, dynamic personalization for sales content, generating code or SQL queries, etc. – all of which requires a specific task focus and grounding to relevant factual information including the enterprise context. And these generic generative LLMs, when subject to such narrow task scenarios in enterprise business use cases, generally tends to generate near approximate content based on whatever pretraining it had – mostly resulting in generative defects which is more commonly termed as hallucination. This is especially so in cases like code generation which requires precision to the last character generated, or an end customer service chat assistant which can be legally responsible for anything it generates, and so on.
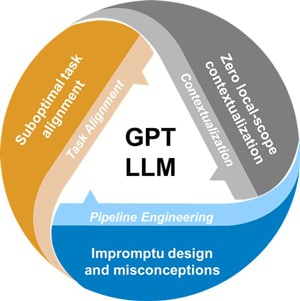
Figure 2. The fundamental limitations of generic GPT LLMs in practical scenarios
Let us take an example of SQL generation based on input text to understand this problem in detail. In a text-to-SQL task, beyond the input text understanding which is an area well handled by most generic LLMs, typically there are three main pivotal factors in generating the right SQL query,
- syntax for the target database technology: this a powerful GPT LLM can handle properly to a good extend but can prove to be resource inefficient.
- understanding of target database schema structure: usually an enterprise internal information which will not and cannot be known to a generic LLM.
- knowledge of business terms, data catalog, derivations etc.: again mostly an enterprise specific information not known to a generic LLM.
So, as we saw here in the example, two of the key factors required are not directly known to a generic generative pre-trained transformer LLM. Though steps and factors might vary, this is true with the case of any type of use case addressing specialized tasks and/or requiring enterprise contextual knowledge. In addition to this contextualization and hallucinations problem, the security risks and ethical concerns are another front of challenges generic LLM brings to the table. With the generative nature of applications involved, the risks are multifold and can be either inherent to the model or perpetrated by another party. This risk is further aggravated by the fact that internal working of a generic LLM is open to any external party as much it is to the implementing enterprise.
Table 1: Detailed explanation of the fundamental challenges faced by generic GPT LLMs when coming to practical business/enterprise use case implementation
| Limitations | Details |
|---|---|
| Suboptimal task alignment | The typical generative pre-trained transformer LLM is highly generalized and trained to address a wide spectrum of tasks. While such a model is highly suitable for general interactive tasks and POCs, it proves to be sub-optimal for task specific enterprise business use cases. In a nutshell, the model might not be optimally tuned for the task specific intent identification, request content understanding, and response generation. While the very large and powerful generic GPT LLMs are capable of many tasks, they can prove to be resource inefficient for business use cases requiring to address only specific tasks. And smaller generic GPT SLMs mostly will have only limited trained tasks. Even in case of large GPTs where the required task is already covered, sometimes the depth of training in the specific task may not be adequate. |
| Zero local-scope contextualization | The generic GPT LLM is pre-trained with public data or other datasets available to the model publishing company/organization. And any response created will be based on cumulative understanding of this data available to them at the time of training, while for a business use case implementation what is required is response contextualized on latest data private to the implementing company/enterprise. This knowledge cut-off gap, between pre-training and the latest factual data local to the business use case scope, results in inaccurate and unexpected response. And while we can term it with fascinating names like hallucination, essentially it is a response the model is forced to generate with whatever limited knowledge it has been trained on. |
| Impromptu design and misconceptions | A common issue now is that, when it comes to LLM implementation the overall pipeline is not being properly designed and engineered. This is stemming heavily from the lack of right frameworks/approaches and misconceptions like llm-can-do-anything, larger-the-better, etc. The OpenAI GPT hype has driven heavy investments and research in the core model area resulting in explosion of high performing LLMs. But the focus and progress in implementation approaches, frameworks, and other related dependencies is lagging severely behind. It is more like you have a very powerful GPU but no good enough motherboards to harness its power. This gap has resulted in companies productionizing GenAI solutions without proper pipeline design, right prompt engineering, and guardrails – almost completely relying on assumed GPT LLM capabilities to do the trick – resulting in severe challenges ranging from underperforming applications with inaccurate responses, to legal issues where companies had to honor hallucinated & sycophantic responses, data privacy & ethical issues, high cost of operation, etc. |
In a way a generic GPT LLM can be compared to a wild animal, maybe a wild stallion, which is not tamed - very powerful and has high potential but not domesticated for a purpose. And irrespective of how powerful it is, unless the intended purpose is served rightly, it is not fit for use.
Guideline Solution for Enterprises
Now that we have discussed in detail the fundamental limitations with GPT LLMs when it comes to business implementations, let us see how to address these challenges practically and effectively. And while we do not plan to go into fine-grained details of each solution option, let us try to paint a clear guideline of how to address them.
Like any other use case, the first thing to do is understand the use case. While this looks routine and basic, with GenAI in the mix, implementation teams have started undermining the importance of this step – assuming that LLM model is a magic solution for almost any requirement. These large generic LLM models are of course very powerful but carries the fundamental limitations we discussed earlier which are detrimental for business use case application. Many implementations being tried out now are just relying on the brute force of LLMs, and essentially fails to achieve the objective in most cases and in cases the functional objective is achieved proves to be inefficient. This is where we need to understand the use case and address the limitations of the model effectively to implement an optimal solution.
The solution is straightforward – tame and domesticate the wild GPT model for the exact purpose at hand. So, how do you do it? Let us again start with the analogy of a wild horse and see how to do it.
Table 2: Pragmatic view of the solution approaches to address the limitations of generic GPT LLMs alongside a wild horse domestication analogy
| Wild Horse | GPT LLM | Implementation View |
|---|---|---|
| Suitably select and tame for intended purpose | Select right model(s) and train/finetune for the intended task and use case | It is important to select the right model(s), which can optimally address the task in efficient and sustainable way. Whether the model needs to be a generic, domain-specific, narrow, large/small, multimodal, any other architecture type, or a combination system all depends on the task and use case at hand. Finally, the need is that the model should optimally aligned for the task and use case. If the selected model is not already trained for the task at hand (like language translation, customer support, code generation etc.), it needs to be trained or rather finetuned to understand and respond as expected for the task. And for this, various finetuning methodologies can be followed like instruction based, few-shot, sequential, parameter efficient (PEFT) methods, reinforcement based (RLHF) approaches, etc. For most business cases, we should be selecting right fitting domain-specific/narrow LLM or finetune one if not directly available and use generic models only if the use case itself is generic enough. |
| Properly leash/tack and feed for the task | Anchor to the local context with access to relevant information | Once we have the fitting model with the right task alignment, the next need is contextualization – where the LLM model/system should respond with contextually accurate content in an expected manner. And in most cases, the contextual information is local/private to the enterprise requiring access to these business application with relevant and latest information. For the use case required contextualization and relevant data access we can leverage options including RAG methods like CRAG, GNN-RAG, RAFT, AdaptiveRAG Chain (References #9), etc. and as well various finetuning techniques which can even extend to self-learning loops. Essentially, the model/application should be able to respond taking into consideration the right and latest facts specific to the area of the ask. |
| Ensure to groom well and rightly instruct | Leverage apt frameworks, prompts, and guardrails | While the LLM model individually could be high performing, for practical application what matters is the end-to-end solution of which LLM model is one of the components. The solution should be properly designed and engineered to bring together various components, both AI and non-AI, from context to prompts, security and other capabilities - leveraging LLM implementation frameworks and specialized agents as applicable. The model should be requested with the right prompts for the task based on how it was trained/tuned to understand. At the same time the implementation should be secured by guardrails against both external threats and inherent model risks including unwarranted data exposure, unintentional bias, and other threats. This is especially important in current scenario where LLMs are competing to increase the context window to improve performance, but this seems to come at a cost of increased security risk potential like many-shot jailbreaking. At overall level, we need to engineer the LLM pipeline to bring together the right capabilities to optimally address the use case and respond considering factual & relevant content while ensuring to be secure & responsible. |
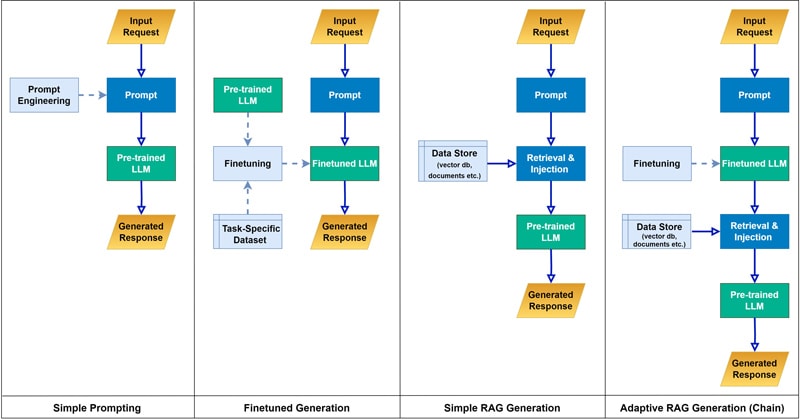
The below illustrative schematic (Figure 3) gives a sneak peek view of how the earlier mentioned challenges in implementation of GPT LLMs can be addressed. It depicts a simplified view of four different implementation approaches for LLM applications, and we will use these as examples to compare and understand the solution guidelines we discussed. While we will not get into the detailed design of these implementation options, it gives a good overview of how task alignment, right context, and proper pipeline engineering approach/framework can help with practical implementation of LLMs.
Figure 3. Simplified implementation flow of prompting, finetuning, and RAG methods individually and combined. Solid arrows represent active flows, while the dotted ones represent prior completed steps. (Source: References #9)
Quick understanding of what these design options are and how they compare
- on the far left, it depicts a simple impromptu design with a generic pre-trained LLM and basic prompt engineering where the almost the entirety of success is left to the used LLMs capability and training.
- the 2nd option from left shows a design leveraging LLM finetuned on the specific intended task along with fitting prompt engineering, here there is better task alignment and contextualization but would need expensive finetuning process and might still lack somewhat on getting relevant response generated.
- the 3rd option portrays a design with retrieval augmented generation option (naïve, similarity, etc.), and is capable of pulling relevant content based on input/request, but still may have challenges in contextualization specific to the enterprise/application.
- the last option on the right side illustrates a modular compound chain approach which is combining both finetuning (relatively light tuning on SLM for local context) and retrieval augmented generation aspects together with prompt engineering to achieve better contextualization and fact-based response accuracy.
Experiments based on these options have shown that as we move from designs on left to right, the accuracy and content of the responses have improved by considerable margins – from the far-left simple prompting getting the response incorrect almost every time, to fairly accurate response in individual finetuned and RAG based designs, and even better response in the right most compound chain design. Here the experiment task was SQL statement generation (text-to-SQL), which needs to be accurate both in terms of syntax and local database schema, by understanding the right intent and business context of the user input/question. Also, it is important to note that while we have not covered the security aspects in these designs, safety guardrails are a critical component for productionizing business use cases.
Essentially it is all about aligning, contextualizing, engineering, and securing the GPT LLM for the exact task and use case at hand. Though this can be achieved with a monolithic model, a more practical approach will be a compound AI system where different specialized components come together to address the common purpose. And while there are standard frameworks like LangChain which enable many of the capabilities we discussed, there is no comprehensive package with all the dimensions covered especially when it comes to domain-specific needs. Most of the enterprises seeking to implement enterprise scale LLM applications are now focusing on bespoke solutions and frameworks either leveraging standard frameworks or with a greenfield approach.
Conclusion
To put in a nutshell, a GPT LLMs are very powerful tools with a wide span of capabilities but restricted in practical applicability because of its fundamental limitations. It is intriguing to observe all the myriads of things it can do in a human-like way generating novel contents from question responses, story text, images, to videos and more. But irrespective of how wide spanning the capabilities are, unless the intended business use case is served rightly, it is not fit for enterprise use.
Now to quickly look at these fundamental limitations
- Suboptimal task alignment of GPT LLMs for the specific task at hand
- Zero local scope contextualization to the business use case and content
- Impromptu pipeline design that is not properly engineered and secured, which stems largely from the lack of right frameworks/approaches and prevalent LLM related misconceptions
And the solution guidelines to address the limits can be summarized as
- Selection of right model(s) and finetuning for the intended task and domain if not already aligned
- Anchoring to the business/enterprise context with access to relevant and latest information
- Engineering the pipelines aptly with right frameworks, prompts, and guardrails for the use case
While GPT LLM capabilities are improving by leaps and bounds, the business/enterprise implementation side of things has not yet achieved the desired level of maturity. Approaches like parameter efficient finetuning techniques, retrieval augmented generation variants, domain-specific & narrow models, emerging high-efficiency model architectures, agentic frameworks, response guardrails, and other evolving implementation focused methodologies are steps in the right direction.
References
- Language models: past, present, and future
- A Survey of Large Language Models
- The Evolution of Language Models: A Journey Through Time
- A Brief History of Large Language Models
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- Fine-tune a pretrained model
- Retrieval-Augmented Generation for Large Language Models: A Survey
- The Shift from Models to Compound AI Systems
- RAG vs Finetuning vs Prompt Engineering: A pragmatic view on LLM implementation
- Building Guardrails for Large Language







Subscribe
To keep yourself updated on the latest technology and industry trends subscribe to the Infosys Knowledge Institute's publications
Count me in!