Cloud




Enterprise File Share Transformation Program
Transformation program for focused on real-time business scenario to exit from owned and third-party datacenters across Geo’s to Microsoft Azure hyperscaler. This includes implementation of multiple strategic approaches as part of the transformation journey with Automation at the core of implemented solution. This paper presents an overview of transformation of users / departments / vendors / applications specific file shares from On-prem datacenters to PaaS based cloud native Azure solution.
Insights
- This digital transformation was implemented in real time business scenario in one of the leading top five largest food and beverage companies in North America.
- The main purpose is to effectively templatize the enterprise file share transformation with special reference to Azure native solution.
- The disposition of traditional file shares which forms most widely used mode of information collection, processing and sharing within the corporate critical business functions like finance, taxations, production, etc., departments, factories and interactions with external vendors on data staging and processing by both upstream and downstream applications.
Introduction
Overall Datacenter exit strategies and solutions are very relevant in terms of reapplying it for large scale digital transformations and migration to Azure cloud. The dispositions bucketing across the Legacy Applications, AS400, COTS, Non-SAP Applications, SAP Integrated Applications, and Enterprise File Share Migrations are repeatable and scalable.
Especially, the Enterprise File Share Migrations Architecture and strategy covering across geographies, multiple data centers, userbase is a key highlight involving groundbreaking next generation solution most relevant scalable solution across customers, industries positioning both Infosys and Microsoft with value edge over other Hyperscaler and transformation service providers.
The data analysis, classification and ownership identification were key factors contributing to the right sizing of the Waves for data migration to cloud and have sprint plans for cutover activities. Region specific strategies in data migration and identification of cloud regions were considered addressing the data privacy and legal requirements specific to the respective Geo’s. While we touched upon few of the third-party tools from benchmarking perspective, the primary aim is to have a cost-effective umbrella solution focused on the Organization digital goals and objectives addressing their future business needs and go to market requirements.
The data referred in this paper are indicative and mere reflection of business scenario in real time, and it doesn’t represent any of the actual data/statistics of the business/company.
Client Context:
One of the leading top five largest food and beverage companies in North America, initiated a cloud transformation program covering its business enterprise and to exit its on-premises data centers across the Europe, Middle East & Russia, North America, Asia Pacific geographies.
Enterprise File Share Transformation:
The program objective is to transform the various NetApp, Windows, Linux File shares across Client datacenters to Microsoft Azure native solution. This migration aims to enhance scalability, stability, and security while lowering the costs associated with maintaining on-premises storage infrastructure. The file share migration project aims to consolidate and migrate approximately ~300+TB of data from Europe, Asia, Australia and North America locations to Azure File Shares spread across multiple Azure regions.
This comprehensive transformation including data analysis & classification, segregation, and data migration using latest and greatest of Microsoft Azure tools and technologies. Leveraging technology enablement, the program ensures seamless data migration, enhanced data availability, improved scalability, and robust security.
Europe Geo
Client operations across 33+ countries covering Europe, middle east and Russian region and with more than 13K users were using the File Shares using both windows and NetApp arrays in the Germany third party Datacenter.
The business service regions include Middle East Countries, Russia, and European Countries. These File Shares data varied from Application data, Departmental data, and End User's data. Application data ranges from factory to grain elevator operations data stored and accessed through various upstream and downstream operations like Pentaho from Russia, Italy, AcNielsen from European countries, etc. Departmental usage of the share's ranges from country specific finance departments handling highly secured and very sensitive financial data, quality departments. Marketing departments, etc.
These file shares were distributed amongst 25 NetApp Virtual Services hosted on on-premises and a dedicated Windows Server. The volume of files stored in these shares are around ~25+ Million files, consuming around ~60 Terabytes of data in size. Also, the data center was connected to the Azure cloud using meager 400 Mbps dedicated link only. Secondly the time zone of the usage is also round the clock for both Factory operations and business operations.
| File Share Migration | Europe – No of File Share Clusters/Servers | 1 – Windows Servers 20+ – NetApp vServers |
|---|---|---|
| File Share Metrics | Total Data Size | ~64 TB |
| Total Files Count | ~41 million Files | |
| Total user Count | 13K Users | |
| Application using File Shares | 20 |
North American Geo
Client operations across North American region constitutes corporate HQ and with more than 12K users were using the Windows File Shares in their primary Datacenter and DR Datacenter at strategic locations, it also serves entire United States of America, Argentina, Venezuela, Canada, and few other countries in Latin America.
These File Shares data varied from Enterprise Applications, Departmental data, and End User's data. Application data ranges from factory to grain elevator operations data stored and accessed through various upstream and downstream operations JDE, BODS, Snowflakes, Data Lake, EDI, Tableau, etc. Departmental usage of the share's ranges from Corporate Taxations, finance departments handling highly secured and very sensitive financial data, plant operations, HR departments, etc.
These file shares were distributed amongst 50+ Windows Servers in 11 cluster configurations. The volume of files stored in these shares are around ~198+ Million files, consuming around ~142 Terabytes of data in size. Both Primary and DR data centers connected to the Azure cloud using 10 Gbps and 1 Gbps dedicated link.
| File Share Migration | US 2 Data Centers – No of File Share Clusters/Servers | 11 |
|---|---|---|
| File Share Metrics | Total Data Size | ~142 TB |
| Total Files Count | ~198.5 million Files | |
| Total user Count | Around 12K Users | |
| Application using File Shares | 80 |
ANZ Geo
Client operations across Australia New Zealand region and with more than 2.5K users were using the File Shares using both windows in the Major Sydney Datacenter, along with mini DCs each in JP, NZ and Indonesia.
These file shares were distributed amongst 5+ Windows Servers in 2 cluster configurations, 4 standalone systems. The volume of files stored in these shares are around ~11+ Million files, consuming around ~27 Terabytes of data in size. Both Sydney datacenter, JP, NZ, Indonesia mini DCs connected to the Azure cloud using meager 400 Mbps, 50 Mbps, 150 Mbps and 150 Mbps dedicated link.
| File Share Migration | Aus Datacenter – No of File Share Clusters/Servers | 9 |
|---|---|---|
| File Share Metrics | Total Data Size | ~27 TB |
| Total Files Count | ~11 million Files | |
| Total user Count | 2.5K Users | |
| Application using File Shares | 10 |
Transformation strategy and solution:
Key Influencing Factors:
- User Base - It constitutes across spectrum of regions, countries, and users. Varied Country specific business hours and manufacturing operations. These factors greatly influence in bringing out the solution and understanding the business impact on the day-to-day operations.
- Shares Accessibility - Accumulation of data and usage over the years and across business mergers and acquisitions. Shares are mapped and used through multi modal ways in the likes of FQDN - Full Qualified Domain Name, multiple Alias names.
- Usage modes - Shares are mapped / hard coded into various spreadsheets used by country specific departments or applications. Due to its historical nature, there is no tracker or enablement to find out where these shares are referenced and used across these countries.
- DC Connectivity to Azure - Germany DC only had a 400MBPS dedicated connectivity to Azure from Russelsheim. This is a huge limiting factor to migrate huge and complex data to Azure from the Data center.
- Limited Access and Data Analysis - Transformation team did not have complete view of the data in these shares. Since NetApp Array hosted in 24 Virtual Servers greatly limited the ability to use discovery tools like Matilda to scan for the Applications accessing the shares.
Key Program Objectives:
- Transformation should bring out unified target solution. Solution should be scalable and elastic covering file shares on the different various platform at On-Premises Data centers.
- Migration should focus on Very minimal or zero impact to the file share user base irrespective of Applications, Scripts, Bots, Departments, and individual users.
- Transformation-migration should get executed within hard bound timelines, Non-Negotiable. [Exit Europe Third-Party leased DC before Dec 2023; Exit US based DCs before July 2024; Aus based DC by Oct 2024].
- Data transfer should be secured, verifiable and auditable during the entire migration.
- Seamless migration from on-premises data center to Azure from the Client business usage perspective.
Transformation Solution Highlights:
Solution Approach:
Disposition Key Considerations:
- Transform/Migrate varied On-premises Windows File Server clusters, NetApp vServers, and Linux File Servers
- Have seamless Enterprise suites, custom built Applications compatibility and secured access by external vendors on need basis
- Match IOPS requirements laid out in the current On-Premises BAU environment
- Replace / exit On-Premises NAS devices
- Gain saving over the Third-party storage licenses
- Identify solution that is scalable and accessible across all Geo’s
- Optimum Cost-effectiveness in-terms of Transformation/migration and operational sustainability
Azure Storage based native options:
From File Shares management standpoint, Azure Storage Platform natively provides the flexibility to adopt Azure Files, Azure Blobs along with Azure NetApp Files. While the Azure Blobs focuses on the unstructured data storage and Analytics solutions through Data Lake Storage.
The idea is to choose between Azure Files and Azure NetApp Files as the disposition strategy for transformation of traditional SMB, NFS file shares from various Datacenter’s across the Geos.
| Parameters | Azure Files | Azure NetApp Files |
|---|---|---|
| Powered by | Azure Native | NetApp |
| SMB | SMB 3.1 +; User based Authentication | SMB 3.1 +; User based Authentication |
| NFS | NFS 4.1, Network Security Rules | NFS 3 & 4.1; Dual protocol (SMB and NFSv3, SMB and NFSv4.1) |
| Features | Zonal Redundancy, Moderate capacity-based cost scales | Rich ONTAP Management Capabilities - snapshots, backup, replications across zones, regions |
| Pricing | granular pricing across various provisions | Minimum 1TB provision and addition in increments of 1TB |
| Pricing Scenario: 200TB standard storage, LRS | $18,828 / Month; $225,935 / Year | $30,912/Month; $370,949/Year + One off setup cost |
Disposition – Strategic Decision: The decision was to go with Azure Files based on the business needs, performance requirements, and long-term cost considerations.
Migration Key Considerations
- Non-negotiable migrations timelines across the Geo’s based on the datacenter exit milestones.
- Wider ~27.5 K user base spread across 38+ countries 4 major Geo’s.
- File shares are extensively consumed by Enterprise applications, region specific applications, Plants, operations centers, departments and vendors.
- Factor in the 24x7 working mode of plants, operations centers. Month end, Quarter end, Yearly activities performed by critical departments like Taxation, Finance, etc.
In a comparative scenario on having traditional migration with that of DFS N based migration addressing the key considerations from business perspective.
| Traditional Migration Risks | Mitigation |
|---|---|
| Owners can \not be contacted to plan their migration without application to owner mapping (~70% of shares don’t have this mapping today). | This risk cannot be mitigated within the required timelines. |
| Creates a dependency between parallel Migration & Other major Application migration timelines. | Accelerate the process of owner identification to achieve 100% coverage for PO, BODS, Control M and applications related files hares. Respective owners need to develop, test and implement the change before early exit milestones. |
| Everybody (Application / Scripts / Departments / Users / Vendors) must repoint. | Accelerate and complete owner identification for all the file shares. |
| User's File share Migration will break if the repointing is not done by the respective individual users. | Migrate to OneDrive or similar solution. |
| DFS-N based Migration Risks | Mitigation |
|---|---|
| The DFS-N approach means existing Folder path is carried over to Azure. | Initiate the activity to directly repoint to AFS of pending unresolved users, scripts and applications. |
| As Prod and non-Prod files are migrated at the same time, testing is feasible only during a dedicated cutover window. | DFS-N approach is a trusted technical solution. Within Client’s landscape, identify PoC File shares could be migrated through DFS-N within shorter period to prove this works. |
| Folder re-direction may be down if DFS-N server(s) are not available. | DFS-N will be hosted on a cluster in High Availability Zone. |
Migration – Strategic Decision: The decision was to go with DFS-N based migration addressing the business needs, program hard milestones, and seamless user experience.
Execution Approach:
Europe Geo:
Phase I: Secured Data Migration
- Focus on offline bulk data transfer through Microsoft Azure Data box in compliance to the industry standard and Client Data Security policies.
- Azure West Europe region is identified to execute effective data transfer and Phase II migration waves.
Phase II: Migrate logically grouped Countries in Waves
- Agile based Sprints/Waves of migration by logically grouping the region/countries that are part of the Geos covering Middle East, Russia, European Region.
- Prioritize Quick Win, execute native migration covering on premises Windows based File Shares to Azure.
- Subsequently, focus independently on the NetApp Array based file shares migration.
Sample migration implementation structure - overview
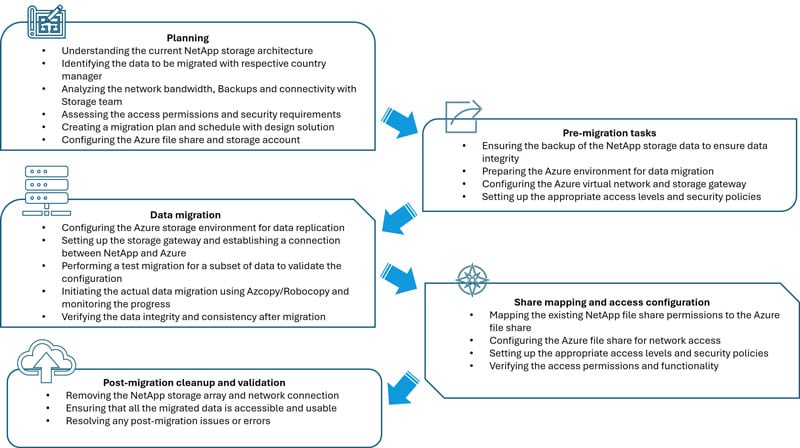
North America and ANZ Geos’:
Phase I: Secured Data Migration
- Continuous Improvement: Strategic shift from Databox as tool to Microsoft Storage Mover as tool of choice for both the Initial Data Copy and for the Delta Sync activities.
- Azure East US II region identified as destination to execute data transfer for North America Geo datacenters.
- Australia East region as the destination for Australia datacenter and New Zealand mini datacenter.
- Singapore – Southeast Asia region as the destination for Japan and Indonesia mini datacenters.
Phase II: Migrate logically grouped Countries in Waves
- Agile based Sprints/Waves of migration by logically grouping based on the virtual file servers.
- Prioritize Quick Wins, identified business criticality and low critical and less data waves. These were mixed and sequenced based on the month end activities, financial closures to arrive at continuous waves-based execution without major gaps in the schedule.
Data Analysis:
Understanding the construct of the data at on Premises is a Key Success Factor for the File share transformation. It involves various layers of analysis that provides deep insight on to the distributed file share data.
From the usage standpoint, File Share are widely used by
- User groups within the client organization, like
- Individual users; For example: MDM users, AVD users, Generic ID based users
- Program/ projects users
- Departmental users; For example: Finance, Taxation
- Factory Operations; For example: Schedule X
- Applications
- Enterprise Applications; For example: JDE, Snowflake, etc.
- Up-stream / Down-stream data transfer.
- FTP / SFTP / Staging data transfer; For example: Bloomberg data.
- Job runs; for example: Control M.
- Corporate reporting; for example: Tableau.
- Custom Applications, Scripts, Automations, etc.
- Third Party Vendors, Tools
- for example: Zarpac
User Access based Data traffic
File Shares are typically accessed / authenticated based on the Active Directory ACLs. Over a period, access is provisioned to wider groups across the organization. The primary challenge is to associate the AD IDs with the users, applications, etc. Also, it is not necessarily providing the insight about who are active current users, it just provides a laundry list of all of IDs having access to the shares.
Below are few of tools considered for access-based data traffic capture
- Treesize premium
- It provides the enhanced statistics on files, folders, space usage, allocated storage, utilized storage, last accessed time, IDs having access to the shares.
- ActvUsrTrail Autobot
- This is an Infosys custom bot focused on capturing the active sessions in a continuous basis or time range-based data capture. This provides more enhanced way of active user session capture aiding more comprehensive data analysis.
- Users / stakeholders workshop
- Data collected by other tools provide either more extensive data or time range limited data set for analysis.
- It is important to engage with the users / stakeholders to understand the data nuances in terms of access, usage, criticality, time sensitive data, user groups, purpose, etc..
Example Scenario: When engaging specific factory-based users, we identified set of external contract workers using generic IDs to access specific share data. Adding to the complexity these IDs were created historically with never expire password and is not compatible with Kerberos ticket authentication-based access to Azure files.
Solution: We took an elaborate step working Domain Authentication Management Group to upgrade the ID’s authentication.
IP based data traffic:
Gathering IP based traffic capture to analyze the data usage primarily provides insights into the wider array of Applications. This method requires a workshop-based approach amongst the key stakeholders from the client IT, Network, also CMDB master data to fetch the application mapping the corresponding IP address.
Below are few of tools considered for IP based data traffic capture
- Matilda Discovery Tool
- Matilda Discover automatically discovers all enterprise applications, their configurations and their dependencies on an agentless basis.
- Windows based Active session report
- This is point of time snapshot report available within the windows server to capture the active sessions. Since it is always point in time report, it is not providing comprehensive data capture.
- ActvUsrTrail Autobot
- This is an Infosys custom bot focused on capturing the active sessions in a continuous basis or time range-based data capture. This provides more enhanced way of active session capture aiding more comprehensive data analysis.
Example Scenario: Identified an Application is using Debian O/S community edition. Hence the application is not able to establish connection to the Azure storage account using domain credentials.
Solution: Jobs are updated to use the SAS Tokens to establish the connection with Azure Storage Account.
Example Scenario: While validating ~200+ Linux servers on-prem, identified AFT servers having CIFS file system-based mount points referencing to file shares
Solution: Enabled the Shared AVD User to run the ASN macros through Linux servers mountpoint for AFS file shares
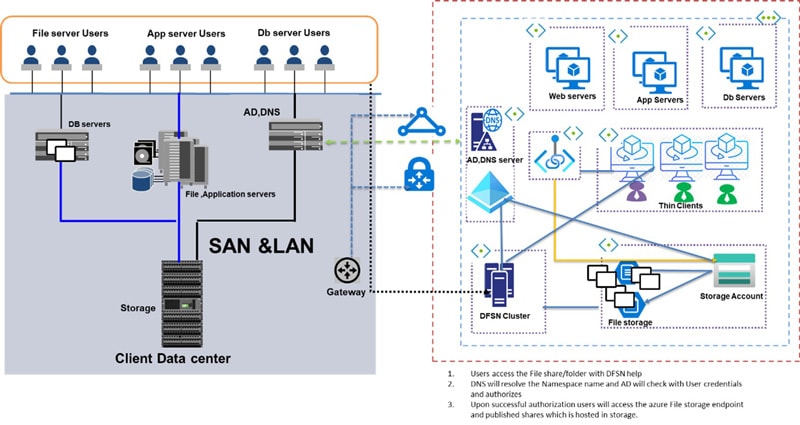
Transformation Overview:
Target state architecture focuses areas
- Target end state post datacenters exit is envisioned in the below depiction
- User are grouped based on access file shares through MDM devices and AVD
- Applications are migrated to Azure and have private endpoint-based access to file shares
- DR solution is enabled through GRS replication
- All access to the file shares is enabled through Private Endpoint, no public access is allowed
- Storage Accounts are integrated with Active directory, ACLs are ported as is from on-prem to Azure
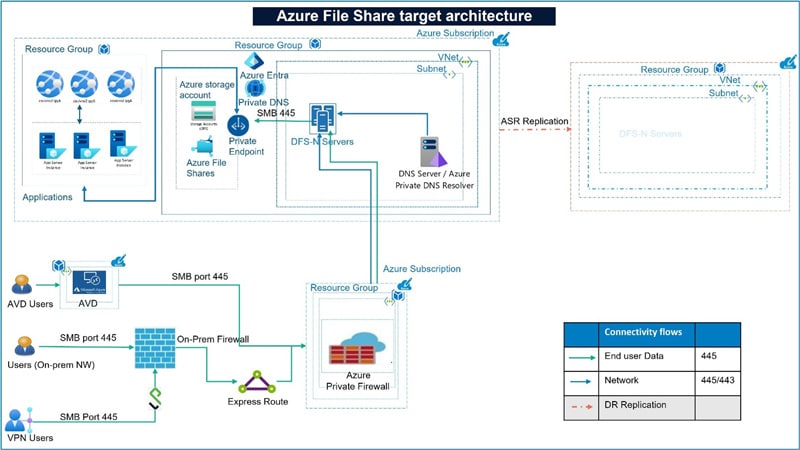
Azure Environment Setup
In an on-premises windows SMB environment, any folder can be mapped or exported as a Share by itself. Hence, it is important to understand the Share structure or to identify the Top/Root level folder in a share. This helps in defining the requirements for creating the Resource Group, Storage Account and subsequently file shares in Azure.
Note: Azure file doesn't have feature to map or export subfolders as a Share by itself.
Parameter required for creating Storage Account and Azure Files:
| Key Parameters | Remarks |
|---|---|
| Access Required on the on-Perm Server | Read/Write & backup operator access to File Server |
| Storage Type | SAN/NAS/NetApp |
| File Share Path | Identify the Shares and corresponding on-perm folder path |
| Storage Protocol | SMB / NFS |
| On-perm utilized storage file server | Overall utilized server storage size |
| Top Level Shares - corresponding storage size | Size mapping at the top-level folders, indicating each share has how much of data stored |
| IOPS - Statistics at the Server level | Throughput measure to understand the system config requirements for designing target disposition |
Additionally,
| Additional Parameters | Remarks |
|---|---|
| Applications accessing the file share | To understand the minimum performance requirements, applications accessing the file shares |
| Users accessing the file share | Volume of users having access and Active users. Their access modes (remote/generic IDs / Network access, etc..) |
| Empty Folders | Identify if the shares are used as staging for vendors/external sites to place files / SFTP, etc.. |
Approach for Storage Account creation:
Storage Account (SA) tier / size to be provisioned based on the above key parameters and inputs collected from the on-prem file shares. Typical scenario standard storage with large file shares enabled 100 TB sizing is provisioned for creating Azure Files. The pricing is generally based on the choice between Standard with utilized storage and Premium storage with Allocated storage, hence 100 TB is a normal sizing practice for creating the Standard SA.
Note: General practice, resource group and storage account creations are executed through pipelines and not handled manually in an enterprise environment. This practice enables the organization to maintain the standards and auto provision the network, security and private endpoint enablement that are established as part of Azure enterprise architecture.
Azure file share creation: Once the Storage Account is created, “Resource Group level – Contributor access” role is to be provisioned for the migration team to create file shares. However, as a standard Azure File are created by the pipelines as appropriate for the respective client organization.
Best Practices:
- File Shares are created typically 1-1 mapping to the Root Level Shares identified on premises file share.
Note:
We had an interesting scenario, one of the on-prem file share had 33K Root Level shares. While it had a larger merger and acquisition-based history as business reason for its existence. Working with client stakeholders, we evolved a strategy to consolidate the data under 4 root folders at Azure Files and had them successfully migrated.
This demands an extensive communication plan reaching to all users to have them make the relevant adjustments post migration accessing their respective files and folders.
- Enable Active Directory domain service authentication for Azure files. This greatly enables the migration of ACLs from on premises to Azure seamlessly.
- Enable soft delete option with 7 days retention to safeguard from accidental user deletion of data.
Data Migration using Data Box:
Enabled initial bulk offline data transfer from Germany data center to Azure - East Europe region.
Microsoft Ordering: Contract Name, Company Name, Datacenter Address, Contact no are required for raising the databox order with Microsoft. Typically, the SLA is 10 business days from the date of order for receiving the Databox at the client datacenter. It is possible Microsoft might split the order into multiple shipments is your order has more than one databox. This shipment also contains the return label from Microsoft for these databoxes. These are to be secured as soon as databoxes are unboxed from the shipment.
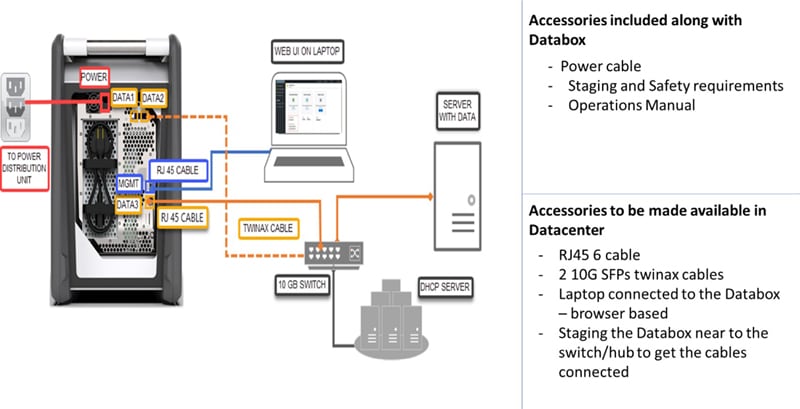
Image reference from: Quickstart for Microsoft Azure Data Box | Microsoft Learn
Learnings using Databox:
RoboCopy to Databox
Robocopy is used to script the data copy from vServers to Databox. Always ensure identification of top-level shares. Robocopy script should the copy only the root / top level shares, else the data gets duplicated in the databox. This has further ramifications when the databox ingesting the data to Azure Files.
Azure Files incompatibility check
Before have the data copied over the Databox, ensure that the source file shares are scanned for the incompatible characters in the folders and file names. While the data gets copied successfully to the databox, it will have a huge impact on getting the data ingested to the Azure files.
Databox Timelines:
- Ordering to Receive the shipment – 10 Business Days
- Hold the Databox to copy the data – 15 Business Days
- Shipment back to Microsoft – 10 Business Days
- Data copy to Azure files - 10 Business Days
Data Migration to Azure:
Net Generation migration product from Microsoft. Worked seamlessly with the Microsoft Storage Mover - Product Engineering team to enable this migration in timely manner.
- Storage Mover Agent image was custom built for this client migration, even before its Azure General Availability / release.
- Migration requirements were tailored to the Storage Mover Agents progressively. This has greatly aided Microsoft to finetune and mature the product for their GA release.
- Daily focused workshops to iron out all the migration team reported bugs and issues by Microsoft Engineering team.
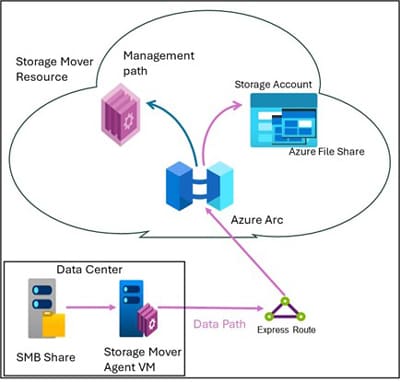
MS - Storage Mover Setup at On Premises:
‘Microsoft Storage Mover’ or ‘Mover’ is new generation product providing fully managed migration service that enables migrating on prem files and folders to Azure Storage seamlessly. It enables managing the migration of globally distributed file shares from a single storage mover resource.
| Activity | Remarks |
|---|---|
| Create an Azure storage mover resource | In Azure, provision Storage Mover in the region where the destination Storage Account is created. |
| Download the azure storage mover agent from Microsoft repository | Download it to the on-premises datacenter where the source file share resides. |
| Install the storage mover agent on the on-prem server | Storage Mover agent to be deployed locally in the same datacenter where the on prem source file share resides. It enables relatively quicker movement of the data between on premises and to destination Azure region. |
| Provision Azure Arc machines and register the agent | Best practice: Based on the experience recommended specification for Arc Machines is “8 CPU & 16 gigs memory along with Ubuntu 22.04.4 LTS”. Please note MS only suggest minimum requirement as 4 CPU and 8GB memory but in practice the performance is better with higher specs. Agent Registration: For the agent registration from on prem to Azure has a pre-requisite of having “Azure ARC Private Link scope” within the same resource group in Azure. |
| Create a project in the Azure Storage Mover | Under the project, jobs are created for data migration from on prem file shares. |
| Create a job definition by giving the source as on-prem file share and destination as azure file share | A project can have collection of multiple jobs for migration. Best practice: Jobs are created with 1-1 mapping to the identified Top-level shares. This greatly enables the migration to have optimum parallel threads in having the data moved to Azure. |
| Maintain and update agents | Periodically, Mover agents are to be updated to the latest of Microsoft images. |
DFS N based seamless user experience
DFS-N based migration to enable zero impact to end users and make it 100% transparent from usage standpoint.
DFS (Distributed File System) Namespaces is a role service in Windows Server that enables to group shared folders located on different servers into one or more logically structured namespaces. This makes it possible to give users a virtual view of shared folders, where a single path leads to files located on multiple servers.
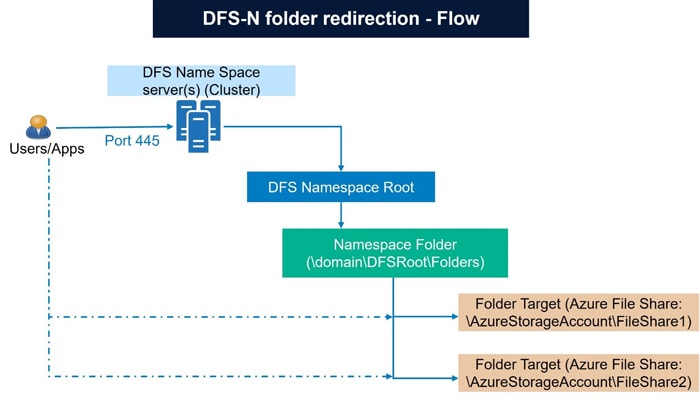
As a prerequisite, have the Active Directory joined with the Private endpoint enabled Azure Storage account with default share level permissions.
While configuring the DFS N especially for the migration from on-premises NetApp environment, do have DFS-N and DFS root consolidation.
During the Cutover activities, runbook should have the following tasks executed for successful implementation of the DFS-N based file share path access.
- DNS Tasks: Remove A record for on-prem server. Point the on-prem server to the DFS-N serve through CNAME creation. Optionally, have the current IP address remapped to some dummy hostname for reference purposes.
- AD Tasks: Establish DFS-N server Service Principals Name (SPN) and have fully qualified domain name as the SPN value similarly for the Alias as well.
Autobots for Data Transformation
SecureAFS Incompatbot
- Autobot based incompatibility scanning of On-premises file shares.
- Autobot based Unicode and Block characters scanning.
RemediAFS Incompatbot
- Autobot based remediation of Azure incompatibility on Folders and File names.
DFSRootbot
- Script based NameSpace and DFSRoots creation.
ActvUsrTrailbot
- To scan for the active user’s session and active sessions accessing the file shares at on-prem datacenter.
AutoPathRemountbot
- Post migration, remounting the paths for the users’ profile on both the MDM based devices and AVD machines.
Value proposition:
- Improved accessibility and collaboration:
Migrating data to azure file shares provided the client stakeholders across Europe, Asia and North America with seamless access to the critical files. This improved global collaboration and real time data sharing. The use of DFS-N ensured that users experience no disruption, maintaining familiar access paths. - Enhanced security and compliance:
By utilizing Azures encryption protocols and access controls by implementing role-based access controls via azure active directory we ensured that data access was strictly managed, aligning with regulatory compliance and internal security policies. - Cost optimization:
By leveraging Azure Hot, cool and transactional optimized tiers, we have optimized storage costs, placing frequently accessed files in more expensive hot storage and less frequently used data in cool storage. This provided flexibility to the customer to scale up/down the storage accordingly. - Operational efficiency:
Centralizing data in azure file shares simplified data management and backup processes. Azure file shares improved data access speeds and reduced latency. - Business continuity and disaster recovery:
Azure infrastructure and geo redundancy provided a reliable platform for data storage, ensuring business continuity even in the event of DR.
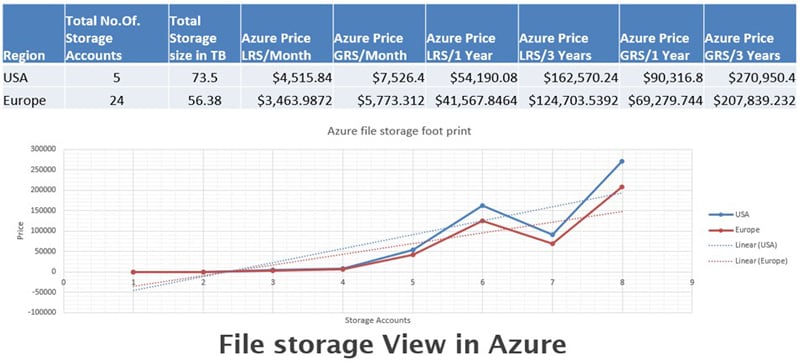
The above table depicts the average OPEX cost component in a sample scenario based on the storage accounts and utilized storage size as an indicative value projection for budgeting purposes.
Transformation Outcome
- File Shares across NA, Europe, ME and Russia successfully transformed on to PaaS based on Azure native solution.
- 111 Million transactions recorded by 12147 users for weekly traffic posted on Azure File Share across North America Geo.
- 100% seamless transformation with user continue to point current mapping path through DFS N implementation.
- 42% savings on licensing and storage cost in comparison with on premises to AFS to the tune of $568K USD 5yrs projection.
Conclusion
The paper presents the research of implementation strategies for Enterprise files share transformation through a systematic approach. The aim is to provide the guided path to begin from the Data Analysis, logical groupings, consolidation of various SMB / NFS based file shares on to umbrella solution with cost effective adoption of Azure native solution.
We analyzed the real time business problem of overarching dependency on file shares with various critical business functions, departments, plants, operation centers, enterprise applications and third-party vendors. Another facet of the File Share transformation also provides a window of opportunity to identify and update the various legacy naming conventions belongs to historically acquired companies, brands still prevalent in the environment. Additionally, historical data dating back to few years up to decades can be classified and dispositions can be applied to get a fresh start to data compliance and security policy implementation.
File Share Transformation at a Glance:
| File Servers | Data Metrics | Data Analysis Approach | Data Migration and Mapping | Infosys innovation – Autobots |
|---|---|---|---|---|
| NetApp | 60TB of file share size, 90+ Million Files, Plants, Offices, Users across 33+Countries | Local IT, Departments, User groups Infosys ActvUsrTrailbot | Databox, Storage Mover, DFS N, md5sum Check, Infy Namespace-DFSRootbot | SecureAFS Incompatbot, RemediAFS Incompatbot |
| SMB | 246TB of file share size, 209+ Million Files, Plants, Offices, Users across 11 Countries | Btree Report, Matilda, Infosys ActvUsrTrailbot | Storage Mover, DFS N, Infy Namespace-DFSRootbot | SecureAFS Incompatbot, RemediAFS Incompatbot |
| NFS | 15TB of file share size, 100+ Million Files, Application Users across 6 Countries | Application Specific, Vendor Specific | R Sync, Robocopy | Infy MultiThrdRSyncbot |
This case study limits itself to the Microsoft cloud native solutions for the enterprise file share transformation. It is primarily due to the hyperscaler choice of the client, and the cost effectiveness compared to the other third-party solution in the like of NetApp on cloud.
Depending on the nature of the client’s requirements some of the third-party solutions like Komprise can be adopted to take advantage of the data life cycle capabilities they offer over the Azure file shares. However, it comes with the additional operational cost and binding to the respective product vendor.
Also, this paper doesn’t discuss the data life cycle management due to its vastness in nature and the expectation is to focus on the Transformation of enterprise file shares from an on-premises datacenter scenario. The overall purpose of paper is to effectively achieve the digital transformation of legacy file shares successfully.
References
Throughout the preparation of this whitepaper, information and insights were drawn from a range of reputable sources, including research papers, articles, and resources. Some of the key references that informed the content of this whitepaper include:
These references provided the foundation upon which the discussions, insights, and recommendations in this whitepaper were based.







Subscribe
To keep yourself updated on the latest technology and industry trends subscribe to the Infosys Knowledge Institute's publications
Count me in!